
Weak Supervision with Snorkel for Multilabel Classification Tasks | by Albers Uzila | May, 2022
Hands-on Tutorials
Label your data programmatically
Table of Contents:· Exploratory Data Analysis
· Keyword Labeling Functions
· Heuristic Labeling Functions
· Labeling Functions with spaCy
· Combining Labeling Function Outputs
· Training a Classifier
· Wrapping Up
There was a radical idea to entirely eliminate hand-labeling any training data in machine learning projects. It birthed snorkel, a powerful library to programmatically build training data.
There are three programmatic operations in snorkel:
- Labeling functions, e.g., using heuristic rules to label data
- Transformation functions, e.g., performing data augmentation
- Slicing functions, e.g., slicing data into subsets for targeted improvement
In this story, we will focus on labeling functions. The key idea is that labeling functions don’t need to be perfectly accurate. Snorkel will combine these output labels from many noisy heuristic labeling strategies to produce reliable training labels.
This process is widely known as Weak Supervision.
Let’s read the dataset and add another column named wordcount, which is the number of words in token.
As you may notice, several problems have tags but many others don’t. The problems that have tags are test problems for the final evaluation of our classifier. These tags are hand-labeled to ensure correctness. The problems that don’t have tags are train problems and to be labeled using weak supervision. We see that there are 135 distinct train problems and 46 distinct test problems.
Train data shape: (135, 4)
Test data shape: (46, 4)
Next, transform the tags in test data into 4 binary columns representing algebra, combinatorics, geometry, and number theory in that order, so we can proceed to modeling, then concatenate the result back to the test data.
To create labeling functions, you need at least some idea of the dataset. Hence, EDA is very important. First off, you can visualize the tokens in a word cloud for each tag.

Some words are strongly associated with a tag. For example, if a problem contains the phrase “real numbers”, then it’s most likely an algebra problem, while geometry problems contain words like “triangle” or “circle”.
Some tokens can be cleaned further such as “let” and “prove” which don’t emphasize any tag since every problem is very possible to have these command words in it. However, since we only do heuristic labeling here, we can just ignore these words in creating labeling functions without doing some extensive cleaning.
Remember wordcount? We can also use this information to form labeling functions.
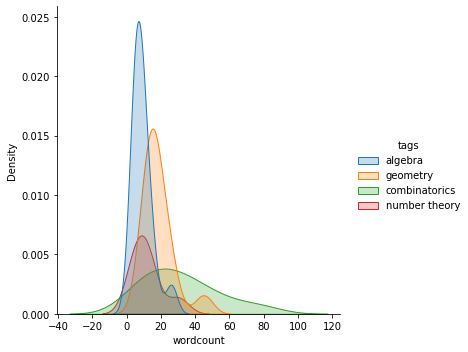
It’s apparent that combinatorics problems are longer: they have many words in them! This makes sense since combinatorics problems sometimes convey some sort of story, such as this one below.
m boys and n girls (m>n) sat across a round table, supervised by a teacher, and they did a game, which went like this. At first, the teacher pointed a boy to start the game. The chosen boy put a coin on the table. Then, consecutively in a clockwise order, everyone did his turn. If the next person is a boy, he will put a coin to the existing pile of coins. If the next person is a girl, she will take a coin from the existing pile of coins. If there is no coin on the table, the game ends. Notice that depending on the chosen boy, the game could end early, or it could go for a full turn. If the teacher wants the game to go for at least a full turn, how many possible boys could be chosen?
We can safely say that a problem that has more than 60 words is a combinatorics problem.
Next, let’s define some variables for easy code readability.
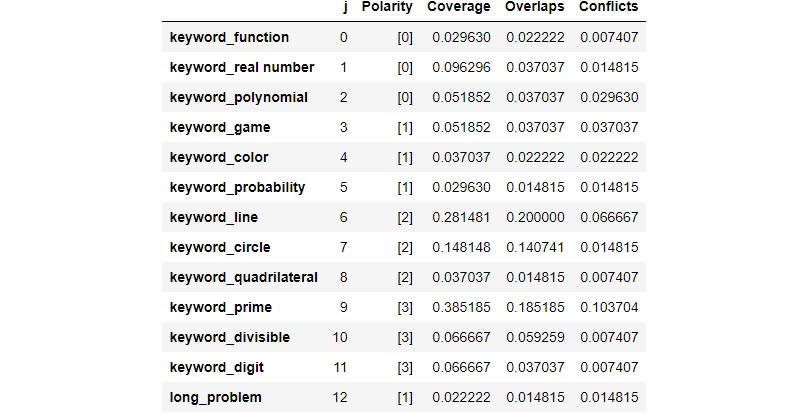
There are several techniques to create labeling functions. The easiest one is using keywords. From EDA, we can pick dominant keywords in each tag. For example, if a problem contains the words “prime” or “integer”, we label it as number theory.
We build 3 keyword labeling functions for each tag, yielding 12 labeling functions in total. Note that some labeling functions have more than one keyword. If a problem has no keywords, then leave it abstain.
One way to make labeling functions is by using LabelingFunction class which accepts a python function that implements the core labeling function logic.
If the true labels of training data are not available such as in our case now, there are 4 summary statistics in snorkel to evaluate labeling functions:
- Polarity: the set of unique labels each labeling function outputs, excluding abstains
- Coverage: the fraction of the dataset each labeling function labels
- Overlaps: the fraction of the dataset where each labeling function and at least another labeling function label
- Conflicts: the fraction of the dataset where each labeling function and at least another labeling function label, and they’re disagree
Since adding false positives will increase coverage, having high coverage is not always good. Labeling functions can be applied to training data using PandasLFApplier class.
100%|███████████████████████████| 135/135 [00:00<00:00, 2327.52it/s]

Next, from EDA, we are agreed that a problem that has more than 60 words is to be labeled as a combinatorics problem. So, let’s make a labeling function to do just that and leave the problems as abstains if their word counts are less than or equal to 60.
Here, we use @labeling_function decorator to make the labeling function as follows, which can be applied to any python function that returns a label for a single observation.
100%|███████████████████████████| 135/135 [00:00<00:00, 4784.38it/s]
Now, for a little bit more advanced implementation, we don’t use raw data as before to derive labeling functions. Instead, we take advantage of the spaCy library, which is made easy by the @nlp_labeling_function decorator in snorkel.
We use spaCy to recognize the entities which are labeled as “PERSON” from the problems. Then these problems are tagged as combinatorics if they contain the entity. This is useful since combinatorics problems, as explained before, sometimes convey some sort of story about a person. Otherwise, leave the problems as abstains.
100%|█████████████████████████████| 135/135 [00:02<00:00, 61.12it/s]
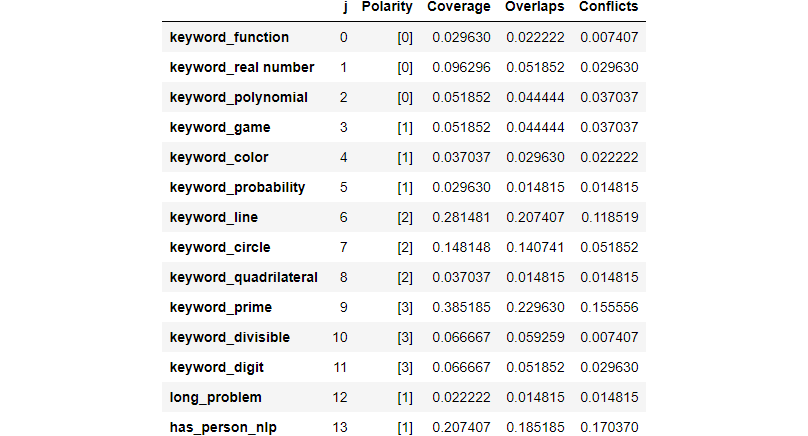
We now have 14 labeling functions, which are expected to overlap or conflict with each other. Snorkel has the ability to combine and denoise their outputs.
But first, let’s create the calc_score function to calculate the weighted precision, recall, and f1 score of the test data between the true and predicted labels.
Don’t forget to also apply the labeling functions to test data as follows, since we can only evaluate the performance of labeling functions on test data.
100%|███████████████████████████████| 46/46 [00:00<00:00, 63.67it/s]
Now, how exactly to combine the outputs from many labeling functions into one or more labels for each observation? A simple way is using what we call MajorityLabelVoter, where the chosen label would be the one that is voted by the majority of labeling functions. To understand how it works, let’s take a look at the first five observations from the test data. We have these labels:
array([[-1, 0, -1, -1, -1, -1, -1, -1, -1, 3, -1, -1, -1, 1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1, 3, -1, -1, -1, -1],
[-1, -1, -1, -1, -1, -1, 2, 2, -1, -1, -1, -1, -1, 1],
[-1, -1, -1, -1, -1, -1, 2, -1, -1, -1, -1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, 2, -1, -1, -1, -1, -1, -1, 1]])
It’s a 5 × 14 matrix since we have 14 labeling functions. Each element represents a label where -1 means abstain. Let’s remove the abstains to see what labels have been chosen.
[0, 3, 1]
[3]
[2, 2, 1]
[2]
[1, 2, 1]
Now it becomes clearer. For example, we can understand that for the third observation (labels displayed as [2, 2, 1] above), 2 out of 14 labeling functions output GEOMETRY and 1 labeling function outputs COMBINATORICS. Let’s call MajorityLabelVoter with cardinality 4 (since there are 4 tags) and see what happens.
array([-1, 3, 2, 2, 1])
We observe that MajorityLabelVoter has three conditions:
- If there’s only one labeling function that votes, it outputs the corresponding label.
- If there’s more than one labeling function vote and one of them votes dominantly, it outputs the dominant label.
- If there’s more than one labeling function vote and two (or more) of them vote equally dominantly, it outputs abstain.
All in all, MajorityLabelVoter outputs a single label for each observation, which is not what we really want since we are working with a multilabel classification task. In fact, snorkel doesn’t natively support multilabel classification.
To solve this problem, we need a workaround. We will use the predict_proba method from MajorityLabelVoter.
array([[0.33333333, 0.33333333, 0. , 0.33333333],
[0. , 0. , 0. , 1. ],
[0. , 0. , 1. , 0. ],
[0. , 0. , 1. , 0. ],
[0. , 1. , 0. , 0. ]])
As expected, it gives a nonzero value to all (dominant) labels equally for each observation. Now, we interpret these nonzero values as labels that are selected by MajorityLabelVoter. In other words, the final label y_pred is a boolean matrix with element 1 if and only if the corresponding element of probs_test is nonzero. Hence the final label prediction is as follows.
array([[1, 1, 0, 1],
[0, 0, 0, 1],
[0, 0, 1, 0],
[0, 0, 1, 0],
[0, 1, 0, 0]])
We see that the labels serve their purpose for the multilabel classification task, i.e. there are some observations with multiple 1s as labels. Calculate the weighted precision, recall, and f1 score using calc_score function.
{'precision': '0.70', 'recall': '0.90', 'f1': '0.77'}
We obtain 0.70 precision, 0.77 f1 score, with suspiciously high recall. However, this is predictable since our method above labels abstains as [1, 1, 1, 1] hence giving many false positives and indirectly leaving a small margin for false negatives.
The output of MajorityLabelVoter is just a set of labels that can be used with the most popular libraries for performing supervised learning. In this story, we use the Logistic Regression from the scikit-learn library. To be precise, we will first extract text features into a matrix of TF-IDF, then employ logistic regression with balanced class weight (to address class imbalance). The model will be trained in a multiclass setting as One-Vs-The-Rest.
Our training data would be df_train with its label y_train, where y_train is a boolean matrix with element 1 if and only if the corresponding element of probs_train is nonzero. However, we need to be careful. There may exist some observations that are not covered in our labeling functions. Hence, we need to filter out these observations using filter_unlabeled_dataframe.
Lastly, train the model, predict on df_test, and calculate the score.
{'precision': '0.83', 'recall': '0.80', 'f1': '0.79'}
We observe an overall boost in scores over the MajorityLabelVoter with no suspiciously high recall! This is in part because the discriminative model generalizes beyond the labeling function’s labels and makes good predictions on all data points, not just the ones covered by labeling functions. The discriminative model can generalize beyond the noisy labeling heuristics.
We’ve been introduced to Weak Supervision, a data labeling method without actually labeling any data (manually). Even though it looks like a cult, weak supervision cuts labeling time from months to days, even hours, with reliable results. We use snorkel to do so, and successfully devise a way to facilitate a multilabel classification task using predict_proba method from MajorityLabelVoter.
The idea of weak supervision is to combine the outputs of many labeling functions which are used to programmatically label data. In our case, we found that this method gives high recall. Then, we showed that a classifier trained on a weakly supervised dataset can outperform an approach based on the labeling functions alone as it learns to generalize beyond the noisy heuristics we provide.
Hands-on Tutorials
Label your data programmatically
Table of Contents:· Exploratory Data Analysis
· Keyword Labeling Functions
· Heuristic Labeling Functions
· Labeling Functions with spaCy
· Combining Labeling Function Outputs
· Training a Classifier
· Wrapping Up
There was a radical idea to entirely eliminate hand-labeling any training data in machine learning projects. It birthed snorkel, a powerful library to programmatically build training data.
There are three programmatic operations in snorkel:
- Labeling functions, e.g., using heuristic rules to label data
- Transformation functions, e.g., performing data augmentation
- Slicing functions, e.g., slicing data into subsets for targeted improvement
In this story, we will focus on labeling functions. The key idea is that labeling functions don’t need to be perfectly accurate. Snorkel will combine these output labels from many noisy heuristic labeling strategies to produce reliable training labels.
This process is widely known as Weak Supervision.
Let’s read the dataset and add another column named wordcount, which is the number of words in token.
As you may notice, several problems have tags but many others don’t. The problems that have tags are test problems for the final evaluation of our classifier. These tags are hand-labeled to ensure correctness. The problems that don’t have tags are train problems and to be labeled using weak supervision. We see that there are 135 distinct train problems and 46 distinct test problems.
Train data shape: (135, 4)
Test data shape: (46, 4)
Next, transform the tags in test data into 4 binary columns representing algebra, combinatorics, geometry, and number theory in that order, so we can proceed to modeling, then concatenate the result back to the test data.
To create labeling functions, you need at least some idea of the dataset. Hence, EDA is very important. First off, you can visualize the tokens in a word cloud for each tag.
Some words are strongly associated with a tag. For example, if a problem contains the phrase “real numbers”, then it’s most likely an algebra problem, while geometry problems contain words like “triangle” or “circle”.
Some tokens can be cleaned further such as “let” and “prove” which don’t emphasize any tag since every problem is very possible to have these command words in it. However, since we only do heuristic labeling here, we can just ignore these words in creating labeling functions without doing some extensive cleaning.
Remember wordcount? We can also use this information to form labeling functions.
It’s apparent that combinatorics problems are longer: they have many words in them! This makes sense since combinatorics problems sometimes convey some sort of story, such as this one below.
m boys and n girls (m>n) sat across a round table, supervised by a teacher, and they did a game, which went like this. At first, the teacher pointed a boy to start the game. The chosen boy put a coin on the table. Then, consecutively in a clockwise order, everyone did his turn. If the next person is a boy, he will put a coin to the existing pile of coins. If the next person is a girl, she will take a coin from the existing pile of coins. If there is no coin on the table, the game ends. Notice that depending on the chosen boy, the game could end early, or it could go for a full turn. If the teacher wants the game to go for at least a full turn, how many possible boys could be chosen?
We can safely say that a problem that has more than 60 words is a combinatorics problem.
Next, let’s define some variables for easy code readability.
There are several techniques to create labeling functions. The easiest one is using keywords. From EDA, we can pick dominant keywords in each tag. For example, if a problem contains the words “prime” or “integer”, we label it as number theory.
We build 3 keyword labeling functions for each tag, yielding 12 labeling functions in total. Note that some labeling functions have more than one keyword. If a problem has no keywords, then leave it abstain.
One way to make labeling functions is by using LabelingFunction class which accepts a python function that implements the core labeling function logic.
If the true labels of training data are not available such as in our case now, there are 4 summary statistics in snorkel to evaluate labeling functions:
- Polarity: the set of unique labels each labeling function outputs, excluding abstains
- Coverage: the fraction of the dataset each labeling function labels
- Overlaps: the fraction of the dataset where each labeling function and at least another labeling function label
- Conflicts: the fraction of the dataset where each labeling function and at least another labeling function label, and they’re disagree
Since adding false positives will increase coverage, having high coverage is not always good. Labeling functions can be applied to training data using PandasLFApplier class.
100%|███████████████████████████| 135/135 [00:00<00:00, 2327.52it/s]
Next, from EDA, we are agreed that a problem that has more than 60 words is to be labeled as a combinatorics problem. So, let’s make a labeling function to do just that and leave the problems as abstains if their word counts are less than or equal to 60.
Here, we use @labeling_function decorator to make the labeling function as follows, which can be applied to any python function that returns a label for a single observation.
100%|███████████████████████████| 135/135 [00:00<00:00, 4784.38it/s]
Now, for a little bit more advanced implementation, we don’t use raw data as before to derive labeling functions. Instead, we take advantage of the spaCy library, which is made easy by the @nlp_labeling_function decorator in snorkel.
We use spaCy to recognize the entities which are labeled as “PERSON” from the problems. Then these problems are tagged as combinatorics if they contain the entity. This is useful since combinatorics problems, as explained before, sometimes convey some sort of story about a person. Otherwise, leave the problems as abstains.
100%|█████████████████████████████| 135/135 [00:02<00:00, 61.12it/s]
We now have 14 labeling functions, which are expected to overlap or conflict with each other. Snorkel has the ability to combine and denoise their outputs.
But first, let’s create the calc_score function to calculate the weighted precision, recall, and f1 score of the test data between the true and predicted labels.
Don’t forget to also apply the labeling functions to test data as follows, since we can only evaluate the performance of labeling functions on test data.
100%|███████████████████████████████| 46/46 [00:00<00:00, 63.67it/s]
Now, how exactly to combine the outputs from many labeling functions into one or more labels for each observation? A simple way is using what we call MajorityLabelVoter, where the chosen label would be the one that is voted by the majority of labeling functions. To understand how it works, let’s take a look at the first five observations from the test data. We have these labels:
array([[-1, 0, -1, -1, -1, -1, -1, -1, -1, 3, -1, -1, -1, 1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1, 3, -1, -1, -1, -1],
[-1, -1, -1, -1, -1, -1, 2, 2, -1, -1, -1, -1, -1, 1],
[-1, -1, -1, -1, -1, -1, 2, -1, -1, -1, -1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, 2, -1, -1, -1, -1, -1, -1, 1]])
It’s a 5 × 14 matrix since we have 14 labeling functions. Each element represents a label where -1 means abstain. Let’s remove the abstains to see what labels have been chosen.
[0, 3, 1]
[3]
[2, 2, 1]
[2]
[1, 2, 1]
Now it becomes clearer. For example, we can understand that for the third observation (labels displayed as [2, 2, 1] above), 2 out of 14 labeling functions output GEOMETRY and 1 labeling function outputs COMBINATORICS. Let’s call MajorityLabelVoter with cardinality 4 (since there are 4 tags) and see what happens.
array([-1, 3, 2, 2, 1])
We observe that MajorityLabelVoter has three conditions:
- If there’s only one labeling function that votes, it outputs the corresponding label.
- If there’s more than one labeling function vote and one of them votes dominantly, it outputs the dominant label.
- If there’s more than one labeling function vote and two (or more) of them vote equally dominantly, it outputs abstain.
All in all, MajorityLabelVoter outputs a single label for each observation, which is not what we really want since we are working with a multilabel classification task. In fact, snorkel doesn’t natively support multilabel classification.
To solve this problem, we need a workaround. We will use the predict_proba method from MajorityLabelVoter.
array([[0.33333333, 0.33333333, 0. , 0.33333333],
[0. , 0. , 0. , 1. ],
[0. , 0. , 1. , 0. ],
[0. , 0. , 1. , 0. ],
[0. , 1. , 0. , 0. ]])
As expected, it gives a nonzero value to all (dominant) labels equally for each observation. Now, we interpret these nonzero values as labels that are selected by MajorityLabelVoter. In other words, the final label y_pred is a boolean matrix with element 1 if and only if the corresponding element of probs_test is nonzero. Hence the final label prediction is as follows.
array([[1, 1, 0, 1],
[0, 0, 0, 1],
[0, 0, 1, 0],
[0, 0, 1, 0],
[0, 1, 0, 0]])
We see that the labels serve their purpose for the multilabel classification task, i.e. there are some observations with multiple 1s as labels. Calculate the weighted precision, recall, and f1 score using calc_score function.
{'precision': '0.70', 'recall': '0.90', 'f1': '0.77'}
We obtain 0.70 precision, 0.77 f1 score, with suspiciously high recall. However, this is predictable since our method above labels abstains as [1, 1, 1, 1] hence giving many false positives and indirectly leaving a small margin for false negatives.
The output of MajorityLabelVoter is just a set of labels that can be used with the most popular libraries for performing supervised learning. In this story, we use the Logistic Regression from the scikit-learn library. To be precise, we will first extract text features into a matrix of TF-IDF, then employ logistic regression with balanced class weight (to address class imbalance). The model will be trained in a multiclass setting as One-Vs-The-Rest.
Our training data would be df_train with its label y_train, where y_train is a boolean matrix with element 1 if and only if the corresponding element of probs_train is nonzero. However, we need to be careful. There may exist some observations that are not covered in our labeling functions. Hence, we need to filter out these observations using filter_unlabeled_dataframe.
Lastly, train the model, predict on df_test, and calculate the score.
{'precision': '0.83', 'recall': '0.80', 'f1': '0.79'}
We observe an overall boost in scores over the MajorityLabelVoter with no suspiciously high recall! This is in part because the discriminative model generalizes beyond the labeling function’s labels and makes good predictions on all data points, not just the ones covered by labeling functions. The discriminative model can generalize beyond the noisy labeling heuristics.
We’ve been introduced to Weak Supervision, a data labeling method without actually labeling any data (manually). Even though it looks like a cult, weak supervision cuts labeling time from months to days, even hours, with reliable results. We use snorkel to do so, and successfully devise a way to facilitate a multilabel classification task using predict_proba method from MajorityLabelVoter.
The idea of weak supervision is to combine the outputs of many labeling functions which are used to programmatically label data. In our case, we found that this method gives high recall. Then, we showed that a classifier trained on a weakly supervised dataset can outperform an approach based on the labeling functions alone as it learns to generalize beyond the noisy heuristics we provide.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.