
What is switchback testing for decision models?
What Is Switchback Testing for Decision Models?
A/B testing for decision models
Switchback testing for decision models allows algorithm teams to compare a candidate model to a baseline model in a true production environment, where both models are making real-world decisions for the operation. With this form of testing, teams can randomize which model is applied to units of time and/or location in order to mitigate confounding effects (like holidays, major events, etc.) that can impact results when doing a pre/post rollout test.
Switchback tests can go by several names (e.g., time split experiments), and they are often referred to as A/B tests. While this is a helpful comparison for orientation, it’s important to acknowledge that switchback and A/B tests are similar but not the same. Decision models can’t be A/B tested the same way webpages can be due to network effects. Switchback tests allow you to account for these network effects, whereas A/B tests do not.
For example, when you A/B test a webpage by serving up different content to users, the experience a user has with Page A does not affect the experience another user has with Page B. However, if you tried to A/B test delivery assignments to drivers — you simply can’t. You can’t assign the same order to two different drivers as a test for comparison. There isn’t a way to isolate treatment and control within a single unit of time or location using traditional A/B testing. That’s where switchback testing comes in.
Let’s explore this type of testing a bit further.
What’s an example of switchback testing?
Imagine you work at a farm share company that delivers fresh produce (carrots, onions, beets, apples) and dairy items (cheese, ice cream, milk) from local farms to customers’ homes. Your company recently invested in upgrading the entire vehicle fleet to be cold-chain ready. Since all vehicles are capable of handling temperature-sensitive items, the business is ready to remove business logic that was relevant to the previous hybrid fleet.
Before the fleet upgrade, your farm share handled temperature-sensitive items last-in-first-out (LIFO). This meant that if a cold item such as ice cream was picked up, a driver had to immediately drop the ice cream off to avoid a sad melty mess. This LIFO logic helped with product integrity and customer satisfaction, but it also introduced inefficiencies with route changes and backtracking.
After the fleet upgrade, the team wants to remove this constraint since all vehicles are capable of transporting cold items for longer with refrigeration. Previous tests using historical inputs, such as batch experiments (ad-hoc tests used to compare one or more models against offline or historical inputs [1]) and acceptance tests (tests with pre-defined pass/fail metrics used to compare the current model with a candidate model against offline or historical inputs before ‘accepting’ the new model [2]), have indicated that vehicle time on road and unassigned stops decrease for the candidate model compared to the production model that has the LIFO constraint. You’ve run a shadow test (an online test in which one or more candidate models is run in parallel to the current model in production but “in the shadows”, not impacting decisions [3]) to ensure model stability under production conditions. Now you want to let your candidate model have a go at making decisions for your production systems and compare the results to your production model.
For this test, you decide to randomize based on time (every 1 hour) in two cities: Denver and New York City. Here’s an example of the experimental units for one city and which treatment was applied to them.
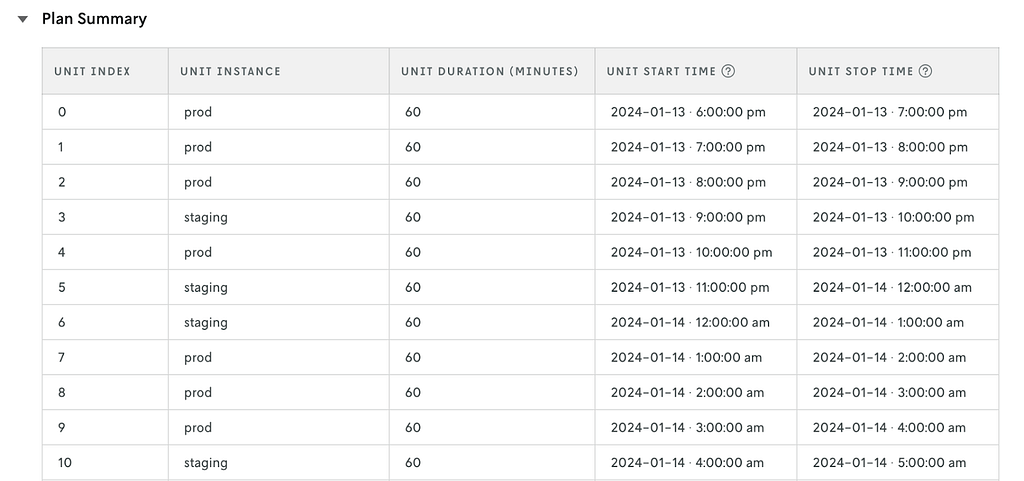
After 4 weeks of testing, you find that your candidate model outperforms the production model by consistently having lower time on road, fewer unassigned stops, and happier drivers because they weren’t zigzagging across town to accommodate the LIFO constraint. With these results, you work with the team to fully roll out the new model (without the LIFO constraint) to both regions.
Why do switchback testing?
Switchback tests build understanding and confidence in the behavioral impacts of model changes when there are network effects in play. Because they use online data and production conditions in a statistically sound way, switchback tests give insight into how a new model’s decision making impacts the real world in a measured way rather than just “shipping it” wholesale to prod and hoping for the best. Switchback testing is the most robust form of testing to understand how a candidate model will perform in the real world.
This type of understanding is something you can’t get from shadow tests. For example, if you run a candidate model that changes an objective function in shadow mode, all of your KPIs might look good. But if you run that same model as a switchback test, you might see that delivery drivers reject orders at a higher rate compared to the baseline model. There are just behaviors and outcomes you can’t always anticipate without running a candidate model in production in a way that lets you observe the model making operational decisions.
Additionally, switchback tests are especially relevant for supply and demand problems in the routing space, such as last-mile delivery and dispatch. As described earlier, standard A/B testing techniques simply aren’t appropriate under these conditions because of network effects they can’t account for.
When do you need switchback testing?
There’s a quote from the Principles of Chaos Engineering, “Chaos strongly prefers to experiment directly on production traffic” [4]. Switchback testing (and shadow testing) are made for facing this type of chaos. As mentioned in the section before: there comes a point when it’s time to see how a candidate model makes decisions that impact real-world operations. That’s when you need switchback testing.
That said, it doesn’t make sense for the first round of tests on a candidate model to be switchback tests. You’ll want to run a series of historical tests such as batch, scenario, and acceptance tests, and then progress to shadow testing on production data. Switchback testing is often a final gate before committing to fully deploying a candidate model in place of an existing production model.
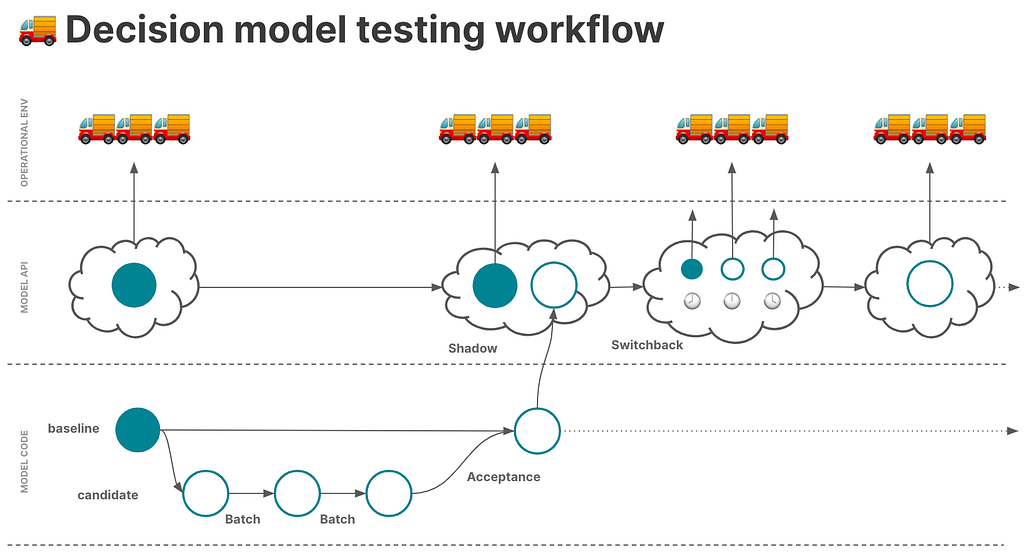
How is switchback testing traditionally done?
To perform switchback tests, teams often build out the infra, randomization framework, and analysis tooling from scratch. While the benefits of switchback testing are great, the cost to implement and maintain it can be high and often requires dedicated data science and data engineering involvement. As a result, this type of testing is not as common in the decision science space.
Once the infra is in place and switchback tests are live, it becomes a data wrangling exercise to weave together the information to understand what treatment was applied at what time and reconcile all of that data to do a more formal analysis of the results.
A few good points of reference to dive into include blog posts on the topic from DoorDash like this one (they write about it quite a bit) [5], in addition to this Towards Data Science post from a Databricks solutions engineer [6], which references a useful research paper out of MIT and Harvard [7] that’s worth a read as well.
Conclusion
Switchback testing for decision models is similar to A/B testing, but allows teams to account for network effects. Switchback testing is a critical piece of the DecisionOps workflow because it runs a candidate model using production data with real-world effects. We’re continuing to build out the testing experience at Nextmv — and we’d like your input.
If you’re interested in more content on decision model testing and other DecisionOps topics, subscribe to the Nextmv blog.
Disclosures
The author works for Nextmv as Head of Product.
References
[1] R. Gough, What are batch experiments for optimization models? (2023), Nextmv
[2] T. Bogich, What’s next for acceptance testing? (2023), Nextmv
[3] T. Bogich, What is shadow testing for optimization models and decision algorithms? (2023), Nextmv
[4] Principles of Chaos Engineering (2019), Principles of Chaos
[5] C. Sneider, Y. Tang, Experiment Rigor for Switchback Experiment Analysis (2019), DoorDash Engineering
[6] M. Berk, How to Optimize your Switchback A/B Test Configuration (2021), Towards Data Science
[7] I. Bojinov, D. Simchi-Levi, J. Zhao, Design and Analysis of Switchback Experiments (2020), arXiv
What is switchback testing for decision models? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
What Is Switchback Testing for Decision Models?
A/B testing for decision models
Switchback testing for decision models allows algorithm teams to compare a candidate model to a baseline model in a true production environment, where both models are making real-world decisions for the operation. With this form of testing, teams can randomize which model is applied to units of time and/or location in order to mitigate confounding effects (like holidays, major events, etc.) that can impact results when doing a pre/post rollout test.
Switchback tests can go by several names (e.g., time split experiments), and they are often referred to as A/B tests. While this is a helpful comparison for orientation, it’s important to acknowledge that switchback and A/B tests are similar but not the same. Decision models can’t be A/B tested the same way webpages can be due to network effects. Switchback tests allow you to account for these network effects, whereas A/B tests do not.
For example, when you A/B test a webpage by serving up different content to users, the experience a user has with Page A does not affect the experience another user has with Page B. However, if you tried to A/B test delivery assignments to drivers — you simply can’t. You can’t assign the same order to two different drivers as a test for comparison. There isn’t a way to isolate treatment and control within a single unit of time or location using traditional A/B testing. That’s where switchback testing comes in.

Let’s explore this type of testing a bit further.
What’s an example of switchback testing?
Imagine you work at a farm share company that delivers fresh produce (carrots, onions, beets, apples) and dairy items (cheese, ice cream, milk) from local farms to customers’ homes. Your company recently invested in upgrading the entire vehicle fleet to be cold-chain ready. Since all vehicles are capable of handling temperature-sensitive items, the business is ready to remove business logic that was relevant to the previous hybrid fleet.
Before the fleet upgrade, your farm share handled temperature-sensitive items last-in-first-out (LIFO). This meant that if a cold item such as ice cream was picked up, a driver had to immediately drop the ice cream off to avoid a sad melty mess. This LIFO logic helped with product integrity and customer satisfaction, but it also introduced inefficiencies with route changes and backtracking.
After the fleet upgrade, the team wants to remove this constraint since all vehicles are capable of transporting cold items for longer with refrigeration. Previous tests using historical inputs, such as batch experiments (ad-hoc tests used to compare one or more models against offline or historical inputs [1]) and acceptance tests (tests with pre-defined pass/fail metrics used to compare the current model with a candidate model against offline or historical inputs before ‘accepting’ the new model [2]), have indicated that vehicle time on road and unassigned stops decrease for the candidate model compared to the production model that has the LIFO constraint. You’ve run a shadow test (an online test in which one or more candidate models is run in parallel to the current model in production but “in the shadows”, not impacting decisions [3]) to ensure model stability under production conditions. Now you want to let your candidate model have a go at making decisions for your production systems and compare the results to your production model.
For this test, you decide to randomize based on time (every 1 hour) in two cities: Denver and New York City. Here’s an example of the experimental units for one city and which treatment was applied to them.
After 4 weeks of testing, you find that your candidate model outperforms the production model by consistently having lower time on road, fewer unassigned stops, and happier drivers because they weren’t zigzagging across town to accommodate the LIFO constraint. With these results, you work with the team to fully roll out the new model (without the LIFO constraint) to both regions.
Why do switchback testing?
Switchback tests build understanding and confidence in the behavioral impacts of model changes when there are network effects in play. Because they use online data and production conditions in a statistically sound way, switchback tests give insight into how a new model’s decision making impacts the real world in a measured way rather than just “shipping it” wholesale to prod and hoping for the best. Switchback testing is the most robust form of testing to understand how a candidate model will perform in the real world.
This type of understanding is something you can’t get from shadow tests. For example, if you run a candidate model that changes an objective function in shadow mode, all of your KPIs might look good. But if you run that same model as a switchback test, you might see that delivery drivers reject orders at a higher rate compared to the baseline model. There are just behaviors and outcomes you can’t always anticipate without running a candidate model in production in a way that lets you observe the model making operational decisions.
Additionally, switchback tests are especially relevant for supply and demand problems in the routing space, such as last-mile delivery and dispatch. As described earlier, standard A/B testing techniques simply aren’t appropriate under these conditions because of network effects they can’t account for.
When do you need switchback testing?
There’s a quote from the Principles of Chaos Engineering, “Chaos strongly prefers to experiment directly on production traffic” [4]. Switchback testing (and shadow testing) are made for facing this type of chaos. As mentioned in the section before: there comes a point when it’s time to see how a candidate model makes decisions that impact real-world operations. That’s when you need switchback testing.
That said, it doesn’t make sense for the first round of tests on a candidate model to be switchback tests. You’ll want to run a series of historical tests such as batch, scenario, and acceptance tests, and then progress to shadow testing on production data. Switchback testing is often a final gate before committing to fully deploying a candidate model in place of an existing production model.
How is switchback testing traditionally done?
To perform switchback tests, teams often build out the infra, randomization framework, and analysis tooling from scratch. While the benefits of switchback testing are great, the cost to implement and maintain it can be high and often requires dedicated data science and data engineering involvement. As a result, this type of testing is not as common in the decision science space.
Once the infra is in place and switchback tests are live, it becomes a data wrangling exercise to weave together the information to understand what treatment was applied at what time and reconcile all of that data to do a more formal analysis of the results.
A few good points of reference to dive into include blog posts on the topic from DoorDash like this one (they write about it quite a bit) [5], in addition to this Towards Data Science post from a Databricks solutions engineer [6], which references a useful research paper out of MIT and Harvard [7] that’s worth a read as well.
Conclusion
Switchback testing for decision models is similar to A/B testing, but allows teams to account for network effects. Switchback testing is a critical piece of the DecisionOps workflow because it runs a candidate model using production data with real-world effects. We’re continuing to build out the testing experience at Nextmv — and we’d like your input.
If you’re interested in more content on decision model testing and other DecisionOps topics, subscribe to the Nextmv blog.
Disclosures
The author works for Nextmv as Head of Product.
References
[1] R. Gough, What are batch experiments for optimization models? (2023), Nextmv
[2] T. Bogich, What’s next for acceptance testing? (2023), Nextmv
[3] T. Bogich, What is shadow testing for optimization models and decision algorithms? (2023), Nextmv
[4] Principles of Chaos Engineering (2019), Principles of Chaos
[5] C. Sneider, Y. Tang, Experiment Rigor for Switchback Experiment Analysis (2019), DoorDash Engineering
[6] M. Berk, How to Optimize your Switchback A/B Test Configuration (2021), Towards Data Science
[7] I. Bojinov, D. Simchi-Levi, J. Zhao, Design and Analysis of Switchback Experiments (2020), arXiv
What is switchback testing for decision models? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.