
Architecting and Building LLM-Powered Applications
This research article explores the process of building an LLM (Language Model-based Learning) application using document loaders, embeddings, vector stores, and prompt templates. LLMs have become increasingly popular in natural language processing tasks due to their ability to generate coherent and contextually relevant text. This article discusses the importance of LLMs, compares fine-tuning and context injection approaches, introduces LangChain, and provides a step-by-step process for building the LLM app. Python code snippets are included where applicable.
Language is the primary medium through which humans communicate and express their thoughts and ideas. Understanding and processing human language has always been a fundamental challenge in the field of artificial intelligence. With the advancements in natural language processing (NLP), the development of sophisticated language models has paved the way for significant breakthroughs in various NLP tasks.
Language Model-based Learning (LLM) has emerged as a powerful approach to tackling these challenges. LLMs leverage deep learning techniques to model and understand the complex patterns and structures of human language. These models have demonstrated remarkable capabilities in generating coherent and contextually relevant text, enabling them to excel in tasks such as text generation, summarization, translation, and question-answering systems.
LLMs in Natural Language Processing Tasks
The integration of LLMs in natural language processing tasks has revolutionized the way we interact with text data. These models can learn from vast amounts of textual information and capture intricate relationships between words, phrases, and concepts. By leveraging this knowledge, LLMs can generate human-like text that aligns with the given context.
One of the key advantages of LLMs is their ability to generate coherent and contextually relevant text. Unlike traditional rule-based or statistical approaches, LLMs have the capability to generate language that follows grammatical rules, preserves context, and demonstrates a deep understanding of semantic relationships. This enables applications such as text summarization, where LLMs can generate concise and informative summaries by extracting key information from a given document.
Additionally, LLMs have been employed in machine translation systems, where they learn to map input text from one language to another, producing high-quality translations. These models have shown impressive performance, outperforming previous machine translation approaches and bridging the gap between languages.
Coherent and Contextually Relevant Text Generation
The ability of LLMs to generate coherent and contextually relevant text is a result of their training on vast amounts of diverse textual data. These models capture patterns, dependencies, and contextual cues from this data, allowing them to generate text that aligns with the input context.
For example, in text completion tasks, LLMs can generate the most likely continuation of a given sentence, ensuring that the generated text is coherent and relevant to the preceding context. This has practical applications in auto-completion features, where LLMs can predict the next word or phrase as users type, providing real-time suggestions.
Moreover, LLMs have been employed in chatbot systems, enabling conversational agents to generate human-like responses. These models learn from dialogue datasets and generate contextually relevant responses, considering the conversational history to maintain coherence and relevance throughout the conversation.
LLMs have become invaluable in natural language processing tasks, offering the capability to generate coherent and contextually relevant text. The advancements in deep learning techniques, coupled with large-scale training data, have paved the way for LLMs to excel in tasks such as text generation, summarization, translation, and dialogue systems. Harnessing the power of LLMs opens up new possibilities for automating language-related tasks and creating more interactive and intelligent applications.
Fine-Tuning vs. Context Injection
Fine-Tuning LLMs
Fine-tuning is a popular approach in LLM development that involves adapting a pre-trained language model to perform specific tasks. Fine-tuning begins with leveraging a pre-trained LLM, which has been trained on a large corpus of general language data. The pre-training phase enables the model to learn rich linguistic representations and capture the statistical patterns of natural language.
To fine-tune an LLM for a specific task, we start with the pre-trained model and further train it on a task-specific dataset. This dataset consists of labeled examples that are relevant to the target task. During the fine-tuning process, the model’s parameters are adjusted to optimize its performance on the specific task.
Python code for fine-tuning an LLM typically involves several steps:
- Load the pre-trained LLM model
- Prepare the task-specific dataset
- Tokenize the input data
- Fine-tune the model
from transformers import TFAutoModelForSequenceClassification, TFAutoTokenizer
model_name = "bert-base-uncased" # Example pre-trained model
model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = TFAutoTokenizer.from_pretrained(model_name)
task_dataset = ... # Load or preprocess the task-specific dataset
tokenized_data = tokenizer(task_dataset["text"], padding=True, truncation=True, max_length=128)
model.compile(optimizer="adam", loss="binary_crossentropy")
model.fit(tokenized_data, task_dataset["labels"], epochs=3)Fine-tuning offers several advantages. Firstly, it allows for faster development as it leverages the pre-trained model’s language understanding capabilities. Secondly, fine-tuning requires relatively fewer task-specific training examples compared to training from scratch, making it a practical option in scenarios with limited labeled data. Finally, fine-tuned models often demonstrate better performance on downstream tasks compared to models trained from scratch.
However, fine-tuning can be computationally expensive, as the entire model needs to be trained on the task-specific dataset. Additionally, fine-tuning may suffer from a phenomenon called catastrophic forgetting, where the model forgets previously learned knowledge during the fine-tuning process.
Context Injection in LLMs
Context injection, also known as prompt engineering, is an alternative approach to utilizing pre-trained LLMs without extensive fine-tuning. Instead of fine-tuning the entire model, context injection involves injecting specific context or prompts into the pre-trained LLM to guide its output generation for a specific task.
Prompt engineering offers flexibility and faster iteration cycles compared to fine-tuning. Developers can design prompts that incorporate desired input-output behavior and encode task-specific instructions. By carefully engineering prompts, it is possible to generate task-specific outputs from a pre-trained LLM without extensive retraining.
Python code for context injection involves the following steps:
- Load the pre-trained LLM model.
- Define the prompt
- Generate text based on the prompt.
- Evaluate the generated output.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model_name = "gpt2" # Example pre-trained model
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
prompt = "Translate the following English text to French: "
input_text = prompt + "Hello, how are you?" # Example input text
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids)
decoded_output = tokenizer.decode(output[0], skip_special_tokens=True)
print(decoded_output)Context injection allows for fine-grained control over the generated text by providing explicit instructions through prompts. Developers can experiment with different prompts and iterate quickly to achieve the desired output for a specific task. One challenge with context injection is designing effective prompts. The prompts should be carefully crafted to elicit the desired responses while maintaining coherence and contextuality. It requires a deep understanding of the LLM’s capabilities and the task at hand to engineer prompts that yield high-quality outputs.
Comparing Fine-Tuning and Context Injection
Both fine-tuning and context injection have their merits and trade-offs. Fine-tuning offers the advantage of training an LLM specifically for a task, which can lead to superior performance. However, it requires task-specific labeled data and can be computationally expensive.
On the other hand, context injection allows for faster iteration cycles and leverages the pre-trained knowledge of LLMs. It offers more flexibility in guiding output generation by injecting task-specific context. However, it may not achieve the same level of performance as fine-tuning when extensive task adaptation is required.
The choice between fine-tuning and context injection depends on the specific requirements of the task, the availability of labeled data, computational resources, and the desired trade-off between performance and development time.
LangChain: A Framework for LLM Applications
Overview of LangChain: Architecture and Components
LangChain is a powerful framework that provides a modular and efficient architecture for building LLM applications. It offers a streamlined workflow for document loading, text chunking, embedding generation, LLM selection, prompt template creation, and vector store creation. Let’s explore the key components and their functionalities:
- Document Loader: The document loader component handles the loading of documents into the LangChain framework. It supports various document formats such as plain text, PDF, HTML, and more. The document loader ensures efficient and reliable ingestion of documents, enabling seamless integration with the rest of the pipeline.
- Text Chunker: The text chunker component splits the loaded documents into smaller text chunks. This step is particularly useful when dealing with large documents or when processing documents in a distributed manner. Text chunking enables parallel processing and improves the efficiency of subsequent steps, such as embedding generation and LLM inference.
- Embedding Generator: The embedding generator component takes the text chunks and generates embeddings for each chunk. Embeddings capture the semantic information of the text and represent it in a numerical vector form. LangChain leverages state-of-the-art language models and embedding techniques to generate high-quality embeddings that encode the contextual meaning of the text chunks.
- LLM Selector: The LLM selector component allows developers to choose the specific LLM model they want to use for their task. LangChain supports a wide range of pre-trained LLM models, such as GPT, BERT, and Transformer models. Developers can select the most suitable LLM based on their specific requirements, such as language generation, question-answering, or sentiment analysis.
- Prompt Template Creator: The prompt template creator component facilitates the creation of prompt templates for context injection. Prompt templates define the structure and instructions provided to the LLM for generating desired outputs. Developers can design templates that guide the LLM’s behavior and tailor it to the task at hand. Prompt templates can include placeholders for dynamic inputs, allowing for flexible and customizable text generation.
- Vector Store Builder: The vector store builder component creates an efficient vector store for storing the generated embeddings. A vector store is a data structure that organizes and indexes the embeddings, allowing for fast and efficient retrieval. LangChain provides methods for building vector stores that enable efficient similarity searches, clustering, and other operations on the embeddings.
Benefits of Using LangChain
LangChain offers several benefits for building LLM applications:
- Efficient Document Loading: LangChain’s document loader component handles the loading of documents from various formats, ensuring efficient ingestion and seamless integration into the pipeline.
- Chunking Documents for Processing: The text chunker component splits large documents into smaller chunks, enabling parallel processing and improving the efficiency of subsequent steps. This allows for scalable processing of large document collections.
- Seamless Embedding Generation: LangChain leverages advanced language models and embedding techniques to generate high-quality embeddings that capture the contextual meaning of the text chunks. The embedding generator component seamlessly integrates with the rest of the pipeline, enabling efficient embedding generation.
- Flexibility in LLM Selection: LangChain provides a wide range of pre-trained LLM models, giving developers the flexibility to choose the most suitable model for their task. This allows for customization and optimization based on the specific requirements of the application.
- Template-Based Prompt Creation: The prompt template creator component allows developers to design prompt templates that guide the LLM’s output generation. This flexibility enables developers to create context-specific instructions and control the behavior of the LLM without extensive fine-tuning.
- Efficient Vector Store Creation: LangChain’s vector store builder component enables the creation of efficient data structures for organizing and indexing the generated embeddings. This facilitates fast and efficient retrieval of embeddings for various downstream tasks such as similarity searches or clustering.
Python Code for Using LangChain Components
- Load Documents using LangChain
- Split Documents into Text Chunks
- Generate Embeddings
- Define the LLM Model
- Define Prompt Template
- Create a Vector Store
# Load documents using LangChain
from langchain import TextChunker
chunker = TextChunker()
text_chunks = chunker.chunk_documents(documents)
# Generate Embeddings
from langchain import EmbeddingGenerator
embedding_generator = EmbeddingGenerator()
embeddings = embedding_generator.generate_embeddings(text_chunks)
# Define the LLM Model
from langchain import LLMSelector
llm_selector = LLMSelector()
llm_model = llm_selector.select_llm_model("gpt2")
# Define Prompt Template
from langchain import PromptTemplateCreator
template_creator = PromptTemplateCreator()
prompt_template = template_creator.create_template("Translate the following English text to French: {text}")
# Create a Vector Store
from langchain import VectorStoreBuilder
vector_store_builder = VectorStoreBuilder()
vector_store = vector_store_builder.build_vector_store(embeddings)
By leveraging the components provided by LangChain, developers can build efficient and customizable LLM applications. The modular architecture of LangChain enables seamless integration of each component, allowing for flexibility and scalability in building complex NLP pipelines.
LangChain is a powerful framework that provides an efficient and modular architecture for building LLM applications. By leveraging components such as the document loader, text chunker, embedding generator, LLM selector, prompt template creator, and vector store builder, developers can build robust and flexible applications that leverage the capabilities of LLMs for various natural language processing tasks.
Building the LLM Application
Load Documents Using LangChain
To start the LLM application development process, the first step is to load the documents into the LangChain framework. LangChain provides a document loader component that handles the loading of documents from various sources and formats.
- Utilizing Document Loaders: LangChain document loaders support a variety of sources, including local files, remote URLs, databases, or APIs. The document loader abstracts the complexities of loading documents, providing a unified interface for accessing different document sources.
- Handling Different Document Formats: LangChain document loaders are designed to handle various document formats, such as plain text files, PDFs, HTML files, and more. The document loader automatically performs format-specific parsing and extraction, ensuring the extracted text is ready for further processing.
Code Example: Python Script for Document Loading
from langchain import DocumentLoader
# Load documents from a local directory
documents = DocumentLoader.load_documents("path/to/documents")
# Load documents from a remote URL
documents = DocumentLoader.load_documents("https://example.com/documents")
# Load documents from a database or API
documents = DocumentLoader.load_documents_from_database(database_connection)
By using the LangChain document loader, developers can easily handle document loading from various sources and formats, making it convenient to integrate different types of text data into their LLM applications.
Splitting Documents into Text Chunks
Once the documents are loaded, the next step is to split them into smaller text chunks. Text chunking allows for more manageable processing and is particularly useful when dealing with large documents or when parallel processing is required.
- Chunking Strategies: LangChain provides flexibility in choosing the chunking strategy based on the specific requirements of the LLM application. Common strategies include splitting documents into paragraphs, sentences, or fixed-size chunks.
- Balancing Size and Coherence: When splitting documents into text chunks, it is essential to find a balance between the chunk size and maintaining the coherence of the text. Chunking that is too fine-grained may result in fragmented and disconnected text, while chunking that is too coarse may lose important context within the chunks.
Code Example: Chunking Implementation in Python
from langchain import TextChunker
chunker = TextChunker()
# Split documents into paragraphs
paragraphs = chunker.chunk_into_paragraphs(documents)
# Split paragraphs into sentences
sentences = chunker.chunk_into_sentences(paragraphs)
# Split documents into fixed-size chunks
chunk_size = 1000 # Specify the desired chunk size in words
fixed_size_chunks = chunker.chunk_into_fixed_size(documents, chunk_size)
The LangChain text chunker component provides methods to split documents into paragraphs, sentences, or fixed-size chunks. Developers can choose the appropriate chunking strategy based on the specific requirements of their LLM application.
From Text Chunks to Embeddings
After splitting the documents into text chunks, the next step is to transform the text chunks into numerical representations called embeddings. Embeddings capture the semantic information of the text and enable the LLM to understand and process the text.
- Word Embeddings and Sentence Embeddings: LangChain supports both word embeddings and sentence embeddings. Word embeddings represent individual words in a vector space, while sentence embeddings represent the entire sentence or text chunk as a vector.
- Transforming Text Chunks into Embeddings: LangChain leverages popular NLP libraries and pre-trained models to generate embeddings from text chunks. These libraries, such as spaCy, Transformers, or Sentence Transformers, provide efficient and accurate methods for generating high-quality embeddings.
Code Example: Generating Embeddings using Python Libraries
import spacy
nlp = spacy.load("en_core_web_md") # Load pre-trained word embeddings
# Generate word embeddings for individual words
def generate_word_embeddings(text_chunks):
embeddings = []
for chunk in text_chunks:
doc = nlp(chunk)
chunk_embeddings = [token.vector for token in doc]
embeddings.append(chunk_embeddings)
return embeddings
# Generate sentence embeddings for text chunks
def generate_sentence_embeddings(text_chunks):
embeddings = []
for chunk in text_chunks:
doc = nlp(chunk)
chunk_embedding = doc.vector
embeddings.append(chunk_embedding)
return embeddings
# Generate word embeddings for text chunks
word_embeddings = generate_word_embeddings(text_chunks)
# Generate sentence embeddings for text chunks
sentence_embeddings = generate_sentence_embeddings(text_chunks)
In the code example above, the spaCy library is used to load pre-trained word embeddings (en_core_web_md). The generate_word_embeddings function generates word embeddings for individual words in the text chunks, while the generate_sentence_embeddings function generates sentence embeddings for the entire text chunks. These functions iterate over the text chunks, process them using spaCy, and extract the respective embeddings.
By utilizing the appropriate Python libraries and models, developers can easily generate word embeddings or sentence embeddings for the text chunks extracted from the documents, enabling further processing and analysis with LLMs.
Define the LLM to Use
Once the text chunks are transformed into embeddings, the next step is to define the specific LLM model to use for the LLM application. LangChain offers a variety of pre-trained LLM models, such as GPT, BERT, and Transformer models, which can be selected based on the requirements of the task.
- Overview of Available LLMs: LangChain provides an extensive collection of pre-trained LLM models that are specifically designed for various natural language processing tasks. These models have been trained on large corpora and possess a deep understanding of language semantics and grammar.
- Selecting an Appropriate LLM for the Task: When choosing the LLM model, developers should consider the specific requirements of the task. Some LLM models excel in language generation tasks, while others are better suited for question-answering or sentiment analysis. It is essential to select an LLM model that aligns with the desired task and expected performance.
Code Example: Defining LLM Model in Python
from langchain import LLMSelector
llm_selector = LLMSelector()
llm_model = llm_selector.select_llm_model("gpt2")
In the code example above, the LLMSelector component is used to select an LLM model. The select_llm_model function takes an argument specifying the desired LLM model, such as “gpt2”. This function returns an instance of the selected LLM model, which can then be used for further processing and text generation.
By leveraging the LLMSelector component, developers can easily choose the appropriate LLM model for their specific task and seamlessly integrate it into their LLM application.
Define Prompt Templates
After selecting the LLM model, the next step is to define prompt templates that provide instructions or context for the LLM’s text generation. Prompt templates guide the LLM in generating coherent and contextually relevant outputs for specific tasks.
- Designing Prompt Templates for LLMs: Prompt templates should be designed to elicit the desired responses from the LLM while maintaining coherence and contextuality. Developers can incorporate dynamic placeholders within the templates to inject task-specific inputs or parameters into the generated text.
- Incorporating Contextual Information: Prompt templates can include context-specific information that helps the LLM understand the desired behavior or generate task-specific outputs. This contextual information can be in the form of explicit instructions, example inputs, or specific constraints.
Code Example: Creating Prompt Templates in Python
from langchain import PromptTemplateCreator
template_creator = PromptTemplateCreator()
# Create a prompt template for translation task
translation_template = template_creator.create_template("Translate the following English text to French: {text}")
# Create a prompt template for summarization task
summarization_template = template_creator.create_template("Summarize the given text: {text}")
In the code example above, the PromptTemplateCreator component is used to create prompt templates for different tasks. The create_template function takes a string as input, where the placeholder {text} represents the dynamic text that will be provided as input during text generation. Developers can create prompt templates tailored to their specific task requirements and desired LLM behavior.
By incorporating prompt templates into the LLM application, developers can guide the LLM’s text generation process and elicit contextually relevant outputs for different tasks.
Creating a Vector Store
Once the text chunks have been transformed into embeddings and the LLM model and prompt templates have been defined, the next step is to create a vector store. A vector store provides efficient storage and retrieval of the embeddings, enabling quick access to the pre-computed embeddings during the LLM application’s runtime.
- Importance of Vector Stores: Vector stores serve as a centralized repository for the embeddings, eliminating the need to regenerate embeddings for each query or text generation request. Storing the embeddings in a vector store allows for faster processing and reduces computational overhead.
- Efficient Storage and Retrieval of Embeddings: LangChain provides a vector store builder component that facilitates the creation of a vector store from the generated embeddings. The vector store efficiently organizes and indexes the embeddings for easy retrieval based on text chunk identifiers.
Code Example: Building a Vector Store using Python Libraries
from langchain import VectorStoreBuilder
vector_store_builder = VectorStoreBuilder()
# Build a vector store from word embeddings
word_vector_store = vector_store_builder.build_vector_store(word_embeddings)
# Build a vector store from sentence embeddings
sentence_vector_store = vector_store_builder.build_vector_store(sentence_embeddings)
In the code example above, the VectorStoreBuilder component is used to build a vector store. The build_vector_store function takes the generated embeddings as input and creates a vector store. Developers can build separate vector stores for word embeddings and sentence embeddings, depending on the specific requirements of their LLM application.
By creating a vector store, developers can efficiently store and retrieve the pre-computed embeddings, enabling faster text generation and reducing the computational burden during runtime.
The step-by-step process outlined in this section demonstrates how to leverage the LangChain framework for building LLM applications. By loading documents, splitting them into text chunks, generating embeddings, selecting the appropriate LLM model, defining prompt templates, and creating a vector store, developers can build robust and efficient LLM applications that excel in various natural language processing tasks. The provided code snippets demonstrate the implementation of each step using Python and showcase the flexibility and ease of use provided by the LangChain framework.
Conclusion
In this research article, we have explored the process of building an LLM (Language Model) application with document loaders, embeddings, vector stores, and prompt templates using the LangChain framework. We began by discussing the need for LLMs in natural language processing tasks and highlighted their ability to generate coherent and contextually relevant text.
We then delved into the concept of fine-tuning versus context injection, discussing the advantages and considerations of each approach. Fine-tuning involves training a pre-existing LLM on a specific task or dataset, while context injection involves providing contextual information during text generation. Understanding the trade-offs between these approaches is crucial when developing LLM applications.
Next, we introduced LangChain as a powerful framework for building LLM applications. We provided an overview of the architecture and components of LangChain, highlighting its benefits, such as efficient document loading, chunking documents for processing, seamless embedding generation, flexibility in LLM selection, template-based prompt creation, and efficient vector store creation.
We then presented a step-by-step process for developing LLM applications using LangChain. We covered loading documents using LangChain’s document loaders, splitting documents into text chunks, generating embeddings from text chunks, selecting the appropriate LLM model, defining prompt templates, and creating a vector store for efficient storage and retrieval of embeddings.
In conclusion, this research article has demonstrated the importance of LLMs in natural language processing tasks and provided insights into the development of LLM applications using the LangChain framework. The key takeaways from this article include the significance of leveraging pre-trained LLM models, the flexibility offered by the LangChain framework’s modular components, and the benefits of using prompt templates and vector stores for efficient text generation.
Future directions for LLM app development involve exploring advanced techniques for fine-tuning LLMs, integrating additional NLP components into the LangChain framework, and optimizing the performance of vector stores for large-scale applications. As LLMs continue to evolve, there is a vast potential for enhancing the capabilities and efficiency of LLM applications in various domains.
In summary, this research article has provided a comprehensive understanding of building LLM applications using LangChain, showcasing the significance of LLMs in NLP tasks, the step-by-step process for development, and future directions for advancing LLM app development. By leveraging the capabilities of LangChain and harnessing the power of LLMs, developers can create robust and contextually aware applications that excel in natural language processing tasks.
This research article explores the process of building an LLM (Language Model-based Learning) application using document loaders, embeddings, vector stores, and prompt templates. LLMs have become increasingly popular in natural language processing tasks due to their ability to generate coherent and contextually relevant text. This article discusses the importance of LLMs, compares fine-tuning and context injection approaches, introduces LangChain, and provides a step-by-step process for building the LLM app. Python code snippets are included where applicable.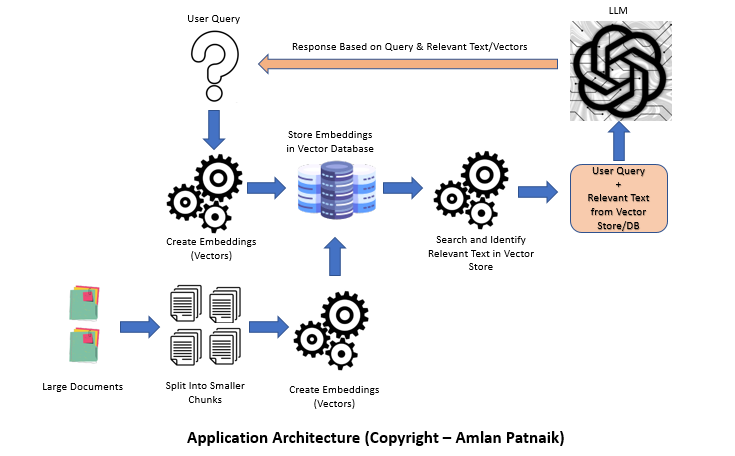
Language is the primary medium through which humans communicate and express their thoughts and ideas. Understanding and processing human language has always been a fundamental challenge in the field of artificial intelligence. With the advancements in natural language processing (NLP), the development of sophisticated language models has paved the way for significant breakthroughs in various NLP tasks.
Language Model-based Learning (LLM) has emerged as a powerful approach to tackling these challenges. LLMs leverage deep learning techniques to model and understand the complex patterns and structures of human language. These models have demonstrated remarkable capabilities in generating coherent and contextually relevant text, enabling them to excel in tasks such as text generation, summarization, translation, and question-answering systems.
LLMs in Natural Language Processing Tasks
The integration of LLMs in natural language processing tasks has revolutionized the way we interact with text data. These models can learn from vast amounts of textual information and capture intricate relationships between words, phrases, and concepts. By leveraging this knowledge, LLMs can generate human-like text that aligns with the given context.
One of the key advantages of LLMs is their ability to generate coherent and contextually relevant text. Unlike traditional rule-based or statistical approaches, LLMs have the capability to generate language that follows grammatical rules, preserves context, and demonstrates a deep understanding of semantic relationships. This enables applications such as text summarization, where LLMs can generate concise and informative summaries by extracting key information from a given document.
Additionally, LLMs have been employed in machine translation systems, where they learn to map input text from one language to another, producing high-quality translations. These models have shown impressive performance, outperforming previous machine translation approaches and bridging the gap between languages.
Coherent and Contextually Relevant Text Generation
The ability of LLMs to generate coherent and contextually relevant text is a result of their training on vast amounts of diverse textual data. These models capture patterns, dependencies, and contextual cues from this data, allowing them to generate text that aligns with the input context.
For example, in text completion tasks, LLMs can generate the most likely continuation of a given sentence, ensuring that the generated text is coherent and relevant to the preceding context. This has practical applications in auto-completion features, where LLMs can predict the next word or phrase as users type, providing real-time suggestions.
Moreover, LLMs have been employed in chatbot systems, enabling conversational agents to generate human-like responses. These models learn from dialogue datasets and generate contextually relevant responses, considering the conversational history to maintain coherence and relevance throughout the conversation.
LLMs have become invaluable in natural language processing tasks, offering the capability to generate coherent and contextually relevant text. The advancements in deep learning techniques, coupled with large-scale training data, have paved the way for LLMs to excel in tasks such as text generation, summarization, translation, and dialogue systems. Harnessing the power of LLMs opens up new possibilities for automating language-related tasks and creating more interactive and intelligent applications.
Fine-Tuning vs. Context Injection
Fine-Tuning LLMs
Fine-tuning is a popular approach in LLM development that involves adapting a pre-trained language model to perform specific tasks. Fine-tuning begins with leveraging a pre-trained LLM, which has been trained on a large corpus of general language data. The pre-training phase enables the model to learn rich linguistic representations and capture the statistical patterns of natural language.
To fine-tune an LLM for a specific task, we start with the pre-trained model and further train it on a task-specific dataset. This dataset consists of labeled examples that are relevant to the target task. During the fine-tuning process, the model’s parameters are adjusted to optimize its performance on the specific task.
Python code for fine-tuning an LLM typically involves several steps:
- Load the pre-trained LLM model
- Prepare the task-specific dataset
- Tokenize the input data
- Fine-tune the model
from transformers import TFAutoModelForSequenceClassification, TFAutoTokenizer
model_name = "bert-base-uncased" # Example pre-trained model
model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = TFAutoTokenizer.from_pretrained(model_name)
task_dataset = ... # Load or preprocess the task-specific dataset
tokenized_data = tokenizer(task_dataset["text"], padding=True, truncation=True, max_length=128)
model.compile(optimizer="adam", loss="binary_crossentropy")
model.fit(tokenized_data, task_dataset["labels"], epochs=3)Fine-tuning offers several advantages. Firstly, it allows for faster development as it leverages the pre-trained model’s language understanding capabilities. Secondly, fine-tuning requires relatively fewer task-specific training examples compared to training from scratch, making it a practical option in scenarios with limited labeled data. Finally, fine-tuned models often demonstrate better performance on downstream tasks compared to models trained from scratch.
However, fine-tuning can be computationally expensive, as the entire model needs to be trained on the task-specific dataset. Additionally, fine-tuning may suffer from a phenomenon called catastrophic forgetting, where the model forgets previously learned knowledge during the fine-tuning process.
Context Injection in LLMs
Context injection, also known as prompt engineering, is an alternative approach to utilizing pre-trained LLMs without extensive fine-tuning. Instead of fine-tuning the entire model, context injection involves injecting specific context or prompts into the pre-trained LLM to guide its output generation for a specific task.
Prompt engineering offers flexibility and faster iteration cycles compared to fine-tuning. Developers can design prompts that incorporate desired input-output behavior and encode task-specific instructions. By carefully engineering prompts, it is possible to generate task-specific outputs from a pre-trained LLM without extensive retraining.
Python code for context injection involves the following steps:
- Load the pre-trained LLM model.
- Define the prompt
- Generate text based on the prompt.
- Evaluate the generated output.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model_name = "gpt2" # Example pre-trained model
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
prompt = "Translate the following English text to French: "
input_text = prompt + "Hello, how are you?" # Example input text
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids)
decoded_output = tokenizer.decode(output[0], skip_special_tokens=True)
print(decoded_output)Context injection allows for fine-grained control over the generated text by providing explicit instructions through prompts. Developers can experiment with different prompts and iterate quickly to achieve the desired output for a specific task. One challenge with context injection is designing effective prompts. The prompts should be carefully crafted to elicit the desired responses while maintaining coherence and contextuality. It requires a deep understanding of the LLM’s capabilities and the task at hand to engineer prompts that yield high-quality outputs.
Comparing Fine-Tuning and Context Injection
Both fine-tuning and context injection have their merits and trade-offs. Fine-tuning offers the advantage of training an LLM specifically for a task, which can lead to superior performance. However, it requires task-specific labeled data and can be computationally expensive.
On the other hand, context injection allows for faster iteration cycles and leverages the pre-trained knowledge of LLMs. It offers more flexibility in guiding output generation by injecting task-specific context. However, it may not achieve the same level of performance as fine-tuning when extensive task adaptation is required.
The choice between fine-tuning and context injection depends on the specific requirements of the task, the availability of labeled data, computational resources, and the desired trade-off between performance and development time.
LangChain: A Framework for LLM Applications
Overview of LangChain: Architecture and Components
LangChain is a powerful framework that provides a modular and efficient architecture for building LLM applications. It offers a streamlined workflow for document loading, text chunking, embedding generation, LLM selection, prompt template creation, and vector store creation. Let’s explore the key components and their functionalities:
- Document Loader: The document loader component handles the loading of documents into the LangChain framework. It supports various document formats such as plain text, PDF, HTML, and more. The document loader ensures efficient and reliable ingestion of documents, enabling seamless integration with the rest of the pipeline.
- Text Chunker: The text chunker component splits the loaded documents into smaller text chunks. This step is particularly useful when dealing with large documents or when processing documents in a distributed manner. Text chunking enables parallel processing and improves the efficiency of subsequent steps, such as embedding generation and LLM inference.
- Embedding Generator: The embedding generator component takes the text chunks and generates embeddings for each chunk. Embeddings capture the semantic information of the text and represent it in a numerical vector form. LangChain leverages state-of-the-art language models and embedding techniques to generate high-quality embeddings that encode the contextual meaning of the text chunks.
- LLM Selector: The LLM selector component allows developers to choose the specific LLM model they want to use for their task. LangChain supports a wide range of pre-trained LLM models, such as GPT, BERT, and Transformer models. Developers can select the most suitable LLM based on their specific requirements, such as language generation, question-answering, or sentiment analysis.
- Prompt Template Creator: The prompt template creator component facilitates the creation of prompt templates for context injection. Prompt templates define the structure and instructions provided to the LLM for generating desired outputs. Developers can design templates that guide the LLM’s behavior and tailor it to the task at hand. Prompt templates can include placeholders for dynamic inputs, allowing for flexible and customizable text generation.
- Vector Store Builder: The vector store builder component creates an efficient vector store for storing the generated embeddings. A vector store is a data structure that organizes and indexes the embeddings, allowing for fast and efficient retrieval. LangChain provides methods for building vector stores that enable efficient similarity searches, clustering, and other operations on the embeddings.
Benefits of Using LangChain
LangChain offers several benefits for building LLM applications:
- Efficient Document Loading: LangChain’s document loader component handles the loading of documents from various formats, ensuring efficient ingestion and seamless integration into the pipeline.
- Chunking Documents for Processing: The text chunker component splits large documents into smaller chunks, enabling parallel processing and improving the efficiency of subsequent steps. This allows for scalable processing of large document collections.
- Seamless Embedding Generation: LangChain leverages advanced language models and embedding techniques to generate high-quality embeddings that capture the contextual meaning of the text chunks. The embedding generator component seamlessly integrates with the rest of the pipeline, enabling efficient embedding generation.
- Flexibility in LLM Selection: LangChain provides a wide range of pre-trained LLM models, giving developers the flexibility to choose the most suitable model for their task. This allows for customization and optimization based on the specific requirements of the application.
- Template-Based Prompt Creation: The prompt template creator component allows developers to design prompt templates that guide the LLM’s output generation. This flexibility enables developers to create context-specific instructions and control the behavior of the LLM without extensive fine-tuning.
- Efficient Vector Store Creation: LangChain’s vector store builder component enables the creation of efficient data structures for organizing and indexing the generated embeddings. This facilitates fast and efficient retrieval of embeddings for various downstream tasks such as similarity searches or clustering.
Python Code for Using LangChain Components
- Load Documents using LangChain
- Split Documents into Text Chunks
- Generate Embeddings
- Define the LLM Model
- Define Prompt Template
- Create a Vector Store
# Load documents using LangChain
from langchain import TextChunker
chunker = TextChunker()
text_chunks = chunker.chunk_documents(documents)
# Generate Embeddings
from langchain import EmbeddingGenerator
embedding_generator = EmbeddingGenerator()
embeddings = embedding_generator.generate_embeddings(text_chunks)
# Define the LLM Model
from langchain import LLMSelector
llm_selector = LLMSelector()
llm_model = llm_selector.select_llm_model("gpt2")
# Define Prompt Template
from langchain import PromptTemplateCreator
template_creator = PromptTemplateCreator()
prompt_template = template_creator.create_template("Translate the following English text to French: {text}")
# Create a Vector Store
from langchain import VectorStoreBuilder
vector_store_builder = VectorStoreBuilder()
vector_store = vector_store_builder.build_vector_store(embeddings)
By leveraging the components provided by LangChain, developers can build efficient and customizable LLM applications. The modular architecture of LangChain enables seamless integration of each component, allowing for flexibility and scalability in building complex NLP pipelines.
LangChain is a powerful framework that provides an efficient and modular architecture for building LLM applications. By leveraging components such as the document loader, text chunker, embedding generator, LLM selector, prompt template creator, and vector store builder, developers can build robust and flexible applications that leverage the capabilities of LLMs for various natural language processing tasks.
Building the LLM Application
Load Documents Using LangChain
To start the LLM application development process, the first step is to load the documents into the LangChain framework. LangChain provides a document loader component that handles the loading of documents from various sources and formats.
- Utilizing Document Loaders: LangChain document loaders support a variety of sources, including local files, remote URLs, databases, or APIs. The document loader abstracts the complexities of loading documents, providing a unified interface for accessing different document sources.
- Handling Different Document Formats: LangChain document loaders are designed to handle various document formats, such as plain text files, PDFs, HTML files, and more. The document loader automatically performs format-specific parsing and extraction, ensuring the extracted text is ready for further processing.
Code Example: Python Script for Document Loading
from langchain import DocumentLoader
# Load documents from a local directory
documents = DocumentLoader.load_documents("path/to/documents")
# Load documents from a remote URL
documents = DocumentLoader.load_documents("https://example.com/documents")
# Load documents from a database or API
documents = DocumentLoader.load_documents_from_database(database_connection)
By using the LangChain document loader, developers can easily handle document loading from various sources and formats, making it convenient to integrate different types of text data into their LLM applications.
Splitting Documents into Text Chunks
Once the documents are loaded, the next step is to split them into smaller text chunks. Text chunking allows for more manageable processing and is particularly useful when dealing with large documents or when parallel processing is required.
- Chunking Strategies: LangChain provides flexibility in choosing the chunking strategy based on the specific requirements of the LLM application. Common strategies include splitting documents into paragraphs, sentences, or fixed-size chunks.
- Balancing Size and Coherence: When splitting documents into text chunks, it is essential to find a balance between the chunk size and maintaining the coherence of the text. Chunking that is too fine-grained may result in fragmented and disconnected text, while chunking that is too coarse may lose important context within the chunks.
Code Example: Chunking Implementation in Python
from langchain import TextChunker
chunker = TextChunker()
# Split documents into paragraphs
paragraphs = chunker.chunk_into_paragraphs(documents)
# Split paragraphs into sentences
sentences = chunker.chunk_into_sentences(paragraphs)
# Split documents into fixed-size chunks
chunk_size = 1000 # Specify the desired chunk size in words
fixed_size_chunks = chunker.chunk_into_fixed_size(documents, chunk_size)
The LangChain text chunker component provides methods to split documents into paragraphs, sentences, or fixed-size chunks. Developers can choose the appropriate chunking strategy based on the specific requirements of their LLM application.
From Text Chunks to Embeddings
After splitting the documents into text chunks, the next step is to transform the text chunks into numerical representations called embeddings. Embeddings capture the semantic information of the text and enable the LLM to understand and process the text.
- Word Embeddings and Sentence Embeddings: LangChain supports both word embeddings and sentence embeddings. Word embeddings represent individual words in a vector space, while sentence embeddings represent the entire sentence or text chunk as a vector.
- Transforming Text Chunks into Embeddings: LangChain leverages popular NLP libraries and pre-trained models to generate embeddings from text chunks. These libraries, such as spaCy, Transformers, or Sentence Transformers, provide efficient and accurate methods for generating high-quality embeddings.
Code Example: Generating Embeddings using Python Libraries
import spacy
nlp = spacy.load("en_core_web_md") # Load pre-trained word embeddings
# Generate word embeddings for individual words
def generate_word_embeddings(text_chunks):
embeddings = []
for chunk in text_chunks:
doc = nlp(chunk)
chunk_embeddings = [token.vector for token in doc]
embeddings.append(chunk_embeddings)
return embeddings
# Generate sentence embeddings for text chunks
def generate_sentence_embeddings(text_chunks):
embeddings = []
for chunk in text_chunks:
doc = nlp(chunk)
chunk_embedding = doc.vector
embeddings.append(chunk_embedding)
return embeddings
# Generate word embeddings for text chunks
word_embeddings = generate_word_embeddings(text_chunks)
# Generate sentence embeddings for text chunks
sentence_embeddings = generate_sentence_embeddings(text_chunks)
In the code example above, the spaCy library is used to load pre-trained word embeddings (en_core_web_md). The generate_word_embeddings function generates word embeddings for individual words in the text chunks, while the generate_sentence_embeddings function generates sentence embeddings for the entire text chunks. These functions iterate over the text chunks, process them using spaCy, and extract the respective embeddings.
By utilizing the appropriate Python libraries and models, developers can easily generate word embeddings or sentence embeddings for the text chunks extracted from the documents, enabling further processing and analysis with LLMs.
Define the LLM to Use
Once the text chunks are transformed into embeddings, the next step is to define the specific LLM model to use for the LLM application. LangChain offers a variety of pre-trained LLM models, such as GPT, BERT, and Transformer models, which can be selected based on the requirements of the task.
- Overview of Available LLMs: LangChain provides an extensive collection of pre-trained LLM models that are specifically designed for various natural language processing tasks. These models have been trained on large corpora and possess a deep understanding of language semantics and grammar.
- Selecting an Appropriate LLM for the Task: When choosing the LLM model, developers should consider the specific requirements of the task. Some LLM models excel in language generation tasks, while others are better suited for question-answering or sentiment analysis. It is essential to select an LLM model that aligns with the desired task and expected performance.
Code Example: Defining LLM Model in Python
from langchain import LLMSelector
llm_selector = LLMSelector()
llm_model = llm_selector.select_llm_model("gpt2")
In the code example above, the LLMSelector component is used to select an LLM model. The select_llm_model function takes an argument specifying the desired LLM model, such as “gpt2”. This function returns an instance of the selected LLM model, which can then be used for further processing and text generation.
By leveraging the LLMSelector component, developers can easily choose the appropriate LLM model for their specific task and seamlessly integrate it into their LLM application.
Define Prompt Templates
After selecting the LLM model, the next step is to define prompt templates that provide instructions or context for the LLM’s text generation. Prompt templates guide the LLM in generating coherent and contextually relevant outputs for specific tasks.
- Designing Prompt Templates for LLMs: Prompt templates should be designed to elicit the desired responses from the LLM while maintaining coherence and contextuality. Developers can incorporate dynamic placeholders within the templates to inject task-specific inputs or parameters into the generated text.
- Incorporating Contextual Information: Prompt templates can include context-specific information that helps the LLM understand the desired behavior or generate task-specific outputs. This contextual information can be in the form of explicit instructions, example inputs, or specific constraints.
Code Example: Creating Prompt Templates in Python
from langchain import PromptTemplateCreator
template_creator = PromptTemplateCreator()
# Create a prompt template for translation task
translation_template = template_creator.create_template("Translate the following English text to French: {text}")
# Create a prompt template for summarization task
summarization_template = template_creator.create_template("Summarize the given text: {text}")
In the code example above, the PromptTemplateCreator component is used to create prompt templates for different tasks. The create_template function takes a string as input, where the placeholder {text} represents the dynamic text that will be provided as input during text generation. Developers can create prompt templates tailored to their specific task requirements and desired LLM behavior.
By incorporating prompt templates into the LLM application, developers can guide the LLM’s text generation process and elicit contextually relevant outputs for different tasks.
Creating a Vector Store
Once the text chunks have been transformed into embeddings and the LLM model and prompt templates have been defined, the next step is to create a vector store. A vector store provides efficient storage and retrieval of the embeddings, enabling quick access to the pre-computed embeddings during the LLM application’s runtime.
- Importance of Vector Stores: Vector stores serve as a centralized repository for the embeddings, eliminating the need to regenerate embeddings for each query or text generation request. Storing the embeddings in a vector store allows for faster processing and reduces computational overhead.
- Efficient Storage and Retrieval of Embeddings: LangChain provides a vector store builder component that facilitates the creation of a vector store from the generated embeddings. The vector store efficiently organizes and indexes the embeddings for easy retrieval based on text chunk identifiers.
Code Example: Building a Vector Store using Python Libraries
from langchain import VectorStoreBuilder
vector_store_builder = VectorStoreBuilder()
# Build a vector store from word embeddings
word_vector_store = vector_store_builder.build_vector_store(word_embeddings)
# Build a vector store from sentence embeddings
sentence_vector_store = vector_store_builder.build_vector_store(sentence_embeddings)
In the code example above, the VectorStoreBuilder component is used to build a vector store. The build_vector_store function takes the generated embeddings as input and creates a vector store. Developers can build separate vector stores for word embeddings and sentence embeddings, depending on the specific requirements of their LLM application.
By creating a vector store, developers can efficiently store and retrieve the pre-computed embeddings, enabling faster text generation and reducing the computational burden during runtime.
The step-by-step process outlined in this section demonstrates how to leverage the LangChain framework for building LLM applications. By loading documents, splitting them into text chunks, generating embeddings, selecting the appropriate LLM model, defining prompt templates, and creating a vector store, developers can build robust and efficient LLM applications that excel in various natural language processing tasks. The provided code snippets demonstrate the implementation of each step using Python and showcase the flexibility and ease of use provided by the LangChain framework.
Conclusion
In this research article, we have explored the process of building an LLM (Language Model) application with document loaders, embeddings, vector stores, and prompt templates using the LangChain framework. We began by discussing the need for LLMs in natural language processing tasks and highlighted their ability to generate coherent and contextually relevant text.
We then delved into the concept of fine-tuning versus context injection, discussing the advantages and considerations of each approach. Fine-tuning involves training a pre-existing LLM on a specific task or dataset, while context injection involves providing contextual information during text generation. Understanding the trade-offs between these approaches is crucial when developing LLM applications.
Next, we introduced LangChain as a powerful framework for building LLM applications. We provided an overview of the architecture and components of LangChain, highlighting its benefits, such as efficient document loading, chunking documents for processing, seamless embedding generation, flexibility in LLM selection, template-based prompt creation, and efficient vector store creation.
We then presented a step-by-step process for developing LLM applications using LangChain. We covered loading documents using LangChain’s document loaders, splitting documents into text chunks, generating embeddings from text chunks, selecting the appropriate LLM model, defining prompt templates, and creating a vector store for efficient storage and retrieval of embeddings.
In conclusion, this research article has demonstrated the importance of LLMs in natural language processing tasks and provided insights into the development of LLM applications using the LangChain framework. The key takeaways from this article include the significance of leveraging pre-trained LLM models, the flexibility offered by the LangChain framework’s modular components, and the benefits of using prompt templates and vector stores for efficient text generation.
Future directions for LLM app development involve exploring advanced techniques for fine-tuning LLMs, integrating additional NLP components into the LangChain framework, and optimizing the performance of vector stores for large-scale applications. As LLMs continue to evolve, there is a vast potential for enhancing the capabilities and efficiency of LLM applications in various domains.
In summary, this research article has provided a comprehensive understanding of building LLM applications using LangChain, showcasing the significance of LLMs in NLP tasks, the step-by-step process for development, and future directions for advancing LLM app development. By leveraging the capabilities of LangChain and harnessing the power of LLMs, developers can create robust and contextually aware applications that excel in natural language processing tasks.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.