
Building an SLM With the Jaro-Winkler Algorithm
Spelling errors are a common problem for many people. They can be caused by a variety of factors, such as typos, mishearing words, or simply not knowing how to spell a word correctly. While spelling errors are usually minor, they can sometimes be embarrassing or even lead to misunderstandings.
The Jaro-Winkler algorithm is one of the many ways that help to accomplish such with a satisfactory result of 0.87 in Mean Average Precision (MAP), and it is a string metric that measures the similarity between two strings. It is a more sophisticated measure than simple edit distance, as it takes into account the transposition of characters and the matching of prefixes and suffixes.
Whether small, medium, or large, the language model is known as a statistical method that predicts the next word in a sequence of words that are trained on various data and learns the probability distribution of words in the language.
In this article, I will show you how to use the Jaro-Winkler algorithm to build a Small Language Model (SLM) with a small fixed-defined dataset that can enhance the system’s spelling checks.
Introduction to J-W
The J-W algorithm is a variation of Damerau-Levenshtein that measures the similarity between two strings, where the substitution of two close characters is considered less critical than the substitution of two characters far from each other.
Common Operations in J-W
1. Substitution
- Input: sent
- Expected output: send
- Substituted letter: d
- Substituted position: 3
2. Deletion
- Input: ssend
- Expected output: send
- Deleted letter: s
- Deleted position: 0
3. Insertion
- Input: snd
- Expected output: send
- Inserted letter: e
- Inserted position: 1
Components of J-W
- Common prefix scaling: This ensures that the agreeing characters must be within half the length of the shorter string.
- Similarity scoring: This calculates a score based on the number of common characters, the number of transpositions, and the length of the strings.
- Distance matcher: This determines whether two strings are similar enough to be considered equal.
- Transpositions evaluation: This evaluates the character from one string that is out of order with the corresponding common character from the other string.
The string comparator value is mostly expressed as:
- s1 and s2 = The concerned strings
- len s1 and len s2 = Length of the concerned strings
- Nc = Common characters counts between the two strings where the distance for common is half of the minimum length of s1 and s2
- Nt = Number of transposition
Small Language Model examples
|
Input |
Expected Matches |
Threshold |
Result summary/Missing letters |
|---|---|---|---|
|
sen |
{sent, send} |
0.941667 |
CLOSE_MATCH, [t,d] |
|
set |
{send, send} |
0.933 |
CLOSE_MATCH, [n] |
|
trasnfr |
{transfer} |
0.9375 |
CLOSE_MATCH, [n, f, e, r] |
|
give |
{give} |
1.0 |
EXACT_MACTH,[] |
Small Language Model Algorithm Implementation
- Step 1: Similarity checks
- Step 2: Calculate the similarity score with J-W algorithm
- Step 3: Comparison of the following:
- similarityScore with expectedSimilarityScore
- similarityScore and threshold
- Step 4: Evaluation of the missing letters
Java Implementation
import org.apache.commons.text.similarity.JaroWinklerSimilarity;
public static SLL checkMatch(String input, Set<String> data) {
JaroWinklerSimilarity jaroWinkler = new JaroWinklerSimilarity();
double threshold = 0.9;
String mappedResult = null;
double highestSimilarity = 0.0;
List<Character> missingWord = new ArrayList<>();
ResultSummary resultSummary = ResultSummary.NO_MATCH;
if (data.contains(input)) {
mappedResult = input;
highestSimilarity = 1.0;
resultSummary = ResultSummary.EXACT_MATCH;
}else {
for (String str : data) {
double similarity = jaroWinkler.apply(input, str);
if (similarity > highestSimilarity && similarity > threshold) {
mappedResult = str;
highestSimilarity = similarity;
resultSummary = ResultSummary.CLOSE_MATCH;
missingWord = new ArrayList<>();
// Find missing characters
int i = 0, j = 0;
while (i < input.length() && j < str.length()) {
if (input.charAt(i) == str.charAt(j)) {
i++;
j++;
} else {
missingWord.add(str.charAt(j));
j++;
}
}
while (j < str.length()) {
missingWord.add(str.charAt(j));
j++;
}
}
}
}
if (mappedResult == null) {
mappedResult = input;
}
return new SLL(input, mappedResult, highestSimilarity, missingWord, resultSummary);
}
Output:
SLL{input="sen", mappedResult="sent", comparisonThreshold=0.9416666666666667, missingWord=[t], resultSummary=CLOSE_MATCH}
SLL{input="set", mappedResult="sent", comparisonThreshold=0.9333333333333333, missingWord=[n], resultSummary=CLOSE_MATCH}
SLL{input="trasnfr", mappedResult="transfer", comparisonThreshold=0.9375, missingWord=[n, f, e, r], resultSummary=CLOSE_MATCH}
SLL{input="wranfer", mappedResult="wranfer", comparisonThreshold=0.0, missingWord=[], resultSummary=NO_MATCH}
SLL{input="ive", mappedResult="give", comparisonThreshold=0.9166666666666666, missingWord=[g], resultSummary=CLOSE_MATCH}
SLL{input="give", mappedResult="give", comparisonThreshold=1.0, missingWord=[], resultSummary=EXACT_MATCH}
SLL{input="took", mappedResult="took", comparisonThreshold=0.0, missingWord=[], resultSummary=NO_MATCH}
SLL{input="tke", mappedResult="take", comparisonThreshold=0.9249999999999999, missingWord=[a], resultSummary=CLOSE_MATCH}
SLL{input="snd", mappedResult="send", comparisonThreshold=0.9249999999999999, missingWord=[e], resultSummary=CLOSE_MATCH}Conclusion
While this is still a work in progress, building SLMs with the Jaro-Winkler algorithm and related algorithms is an exciting approach to improving spellings, and it is better than simple distance editing implementation.
Spelling errors are a common problem for many people. They can be caused by a variety of factors, such as typos, mishearing words, or simply not knowing how to spell a word correctly. While spelling errors are usually minor, they can sometimes be embarrassing or even lead to misunderstandings.
The Jaro-Winkler algorithm is one of the many ways that help to accomplish such with a satisfactory result of 0.87 in Mean Average Precision (MAP), and it is a string metric that measures the similarity between two strings. It is a more sophisticated measure than simple edit distance, as it takes into account the transposition of characters and the matching of prefixes and suffixes.
Whether small, medium, or large, the language model is known as a statistical method that predicts the next word in a sequence of words that are trained on various data and learns the probability distribution of words in the language.
In this article, I will show you how to use the Jaro-Winkler algorithm to build a Small Language Model (SLM) with a small fixed-defined dataset that can enhance the system’s spelling checks.
Introduction to J-W
The J-W algorithm is a variation of Damerau-Levenshtein that measures the similarity between two strings, where the substitution of two close characters is considered less critical than the substitution of two characters far from each other.
Common Operations in J-W
1. Substitution
- Input: sent
- Expected output: send
- Substituted letter: d
- Substituted position: 3
2. Deletion
- Input: ssend
- Expected output: send
- Deleted letter: s
- Deleted position: 0
3. Insertion
- Input: snd
- Expected output: send
- Inserted letter: e
- Inserted position: 1
Components of J-W
- Common prefix scaling: This ensures that the agreeing characters must be within half the length of the shorter string.
- Similarity scoring: This calculates a score based on the number of common characters, the number of transpositions, and the length of the strings.
- Distance matcher: This determines whether two strings are similar enough to be considered equal.
- Transpositions evaluation: This evaluates the character from one string that is out of order with the corresponding common character from the other string.
The string comparator value is mostly expressed as:
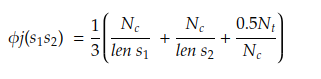
- s1 and s2 = The concerned strings
- len s1 and len s2 = Length of the concerned strings
- Nc = Common characters counts between the two strings where the distance for common is half of the minimum length of s1 and s2
- Nt = Number of transposition
Small Language Model examples
|
Input |
Expected Matches |
Threshold |
Result summary/Missing letters |
|---|---|---|---|
|
sen |
{sent, send} |
0.941667 |
CLOSE_MATCH, [t,d] |
|
set |
{send, send} |
0.933 |
CLOSE_MATCH, [n] |
|
trasnfr |
{transfer} |
0.9375 |
CLOSE_MATCH, [n, f, e, r] |
|
give |
{give} |
1.0 |
EXACT_MACTH,[] |
Small Language Model Algorithm Implementation
- Step 1: Similarity checks
- Step 2: Calculate the similarity score with J-W algorithm
- Step 3: Comparison of the following:
- similarityScore with expectedSimilarityScore
- similarityScore and threshold
- Step 4: Evaluation of the missing letters
Java Implementation
import org.apache.commons.text.similarity.JaroWinklerSimilarity;
public static SLL checkMatch(String input, Set<String> data) {
JaroWinklerSimilarity jaroWinkler = new JaroWinklerSimilarity();
double threshold = 0.9;
String mappedResult = null;
double highestSimilarity = 0.0;
List<Character> missingWord = new ArrayList<>();
ResultSummary resultSummary = ResultSummary.NO_MATCH;
if (data.contains(input)) {
mappedResult = input;
highestSimilarity = 1.0;
resultSummary = ResultSummary.EXACT_MATCH;
}else {
for (String str : data) {
double similarity = jaroWinkler.apply(input, str);
if (similarity > highestSimilarity && similarity > threshold) {
mappedResult = str;
highestSimilarity = similarity;
resultSummary = ResultSummary.CLOSE_MATCH;
missingWord = new ArrayList<>();
// Find missing characters
int i = 0, j = 0;
while (i < input.length() && j < str.length()) {
if (input.charAt(i) == str.charAt(j)) {
i++;
j++;
} else {
missingWord.add(str.charAt(j));
j++;
}
}
while (j < str.length()) {
missingWord.add(str.charAt(j));
j++;
}
}
}
}
if (mappedResult == null) {
mappedResult = input;
}
return new SLL(input, mappedResult, highestSimilarity, missingWord, resultSummary);
}
Output:
SLL{input="sen", mappedResult="sent", comparisonThreshold=0.9416666666666667, missingWord=[t], resultSummary=CLOSE_MATCH}
SLL{input="set", mappedResult="sent", comparisonThreshold=0.9333333333333333, missingWord=[n], resultSummary=CLOSE_MATCH}
SLL{input="trasnfr", mappedResult="transfer", comparisonThreshold=0.9375, missingWord=[n, f, e, r], resultSummary=CLOSE_MATCH}
SLL{input="wranfer", mappedResult="wranfer", comparisonThreshold=0.0, missingWord=[], resultSummary=NO_MATCH}
SLL{input="ive", mappedResult="give", comparisonThreshold=0.9166666666666666, missingWord=[g], resultSummary=CLOSE_MATCH}
SLL{input="give", mappedResult="give", comparisonThreshold=1.0, missingWord=[], resultSummary=EXACT_MATCH}
SLL{input="took", mappedResult="took", comparisonThreshold=0.0, missingWord=[], resultSummary=NO_MATCH}
SLL{input="tke", mappedResult="take", comparisonThreshold=0.9249999999999999, missingWord=[a], resultSummary=CLOSE_MATCH}
SLL{input="snd", mappedResult="send", comparisonThreshold=0.9249999999999999, missingWord=[e], resultSummary=CLOSE_MATCH}Conclusion
While this is still a work in progress, building SLMs with the Jaro-Winkler algorithm and related algorithms is an exciting approach to improving spellings, and it is better than simple distance editing implementation.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.