
Enabling MLOPs in Three Simple Steps | by Dustin Liu | Feb, 2023
With DBT Core, Kedro, and Weights & Biases

I recently engaged in a project involving the implementation of a multiclass classification prediction system utilising financial transactional data, comprising over 10 million records and over 70 classes.
Through this project, I constructed a streamlined end-to-end machine learning operations (MLOPs) infrastructure that is well-suited for this specific use case, while maintaining cost efficiency.
The term MLOPs has a broad range of concepts and definitions, as offered by various vendors or solutions. Some focus on aspects such as training traceability and experimental tracking, while others prioritise feature storage or model deployment. In my understanding, MLOPs is the entire end-to-end process, from data extraction to model deployment and monitoring. However, not all components may be necessary for each use case, and the selection should be based on budget, requirements, and the organisation’s technology maturity.
Let’s walk through the logic of the implementation below.
The starting point, the source of my pain:

As is common with Data Science initiatives, the project initiation utilised Jupyter Notebook (SageMaker Studio in this case) as the primary tool for model development.
- The data was extracted directly from Athena based on tables/views followed by multiple data transformations. There is no direct version control for scripts and no virtualisation for data lineage, code is copied between UAT/Product environment for data extraction.
- Hugging Face Transformers has been integrated to provide access to pre-trained models, and the whole pre-processing features of engineering, training and evaluation are managed within the notebook.
The above process presents significant challenges for those responsible for maintaining it in a production setting, both from a data engineering or machine learning perspective. This includes challenges with troubleshooting, debugging, collaboration on the notebook, and refactoring code within the notebook…the list goes on.
Step 1 — Adding Data Extraction & Transformation Governance

AWS Athena is a robust and efficient serverless service that is designed mainly for ad-hoc SQL query tasks. However, its primary focus on ad-hoc tasks can make it challenging to maintain data lineage and transformation.
While building a dedicated data warehouse may not be cost-effective in this scenario, Athena offers a balance of computation power and cost. To fully leverage Athena’s capabilities and streamline the data extraction process, we need a tool on top of Athena to provide structured data management & processing.
DBT (DBT Core is open source) presents a viable solution for this case. Utilising a well-maintained Athena-Dbt Adapter, data can be probably traced and managed with the various features provided by DBT:
- Data integration: DBT allows for the integration of data from various sources, such as databases, spreadsheets, and APIs, into a single location for analysis and reporting.
- Data modelling: DBT allows users to create and modify data models, including the ability to create relationships between tables and define business logic.
- Data validation: DBT includes built-in validation checks to ensure data integrity and accuracy.
- Data lineage: DBT tracks the lineage of data and allows users to trace data back to its source, providing transparency and accountability.
- Automated testing: DBT includes automated testing capabilities, allowing users to test data models and ensure they are functioning as expected.
- Scheduling and monitoring: DBT allows for the scheduling and monitoring of data pipelines, including the ability to set up alerts and notifications for any issues or errors.
- Documenting and sharing: DBT includes the ability to document and share data models, making it easy for others to understand and use the data.

DBT is a widely adopted open-source tool in the Data Engineering domain and is utilised by many leading companies. As a data engineer, it is essential to have a familiarity with DBT or at least its underlying principles.
Insights of DBT core open-source:


Note: For a detailed explanation of the Athena+DBT integration, please refer to my previous post.
Step 2- Productionalize ML code

After adding DBT to govern the data extraction & transformation phase, the next step is to look into Jupyter Notebook.
Common issues when developing DS/ML code in Jupyter Notebooks include:
- Keeping track of code and output: Jupyter notebooks can become cluttered with code and output, making it difficult to keep track of what has been done and what the current state of the model is.
- Reproducibility: Jupyter notebooks are not always easy to share or reproduce, as they can contain hidden states or other dependencies that are not obvious from the code.
- Debugging: Debugging machine learning code can be difficult in Jupyter notebooks, as the code is often spread across multiple cells and it can be hard to see the entire state of the system at any given time.
- Version control: Jupyter notebooks are not well-suited for version control, as the output and other metadata are stored in the notebook file itself, making it hard to diff or merge changes.
- Dependency management: Jupyter notebooks can make it difficult to manage dependencies and ensure that the code runs on different machines or in different environments.
- No integrated auto-testing capability
The Jupyter Notebook is not equipped for production readiness and can prove costly for organisations that need to hire MLE to productionlise code from it.
Kedro offers a solution to this challenge by providing an open-source Python framework that facilitates the creation of reproducible, maintainable, and modular data science code. It incorporates software engineering best practices to enable the development of production-ready data science pipelines.
Code is developed in the Kedro framework and can be deployed to SageMaker Studio (this is only one of many supported deployments) for enhanced computing power like GPU.

Kedro was initially developed by QuantumBlack, AI by Mckinsey and is now hosted by the LF AI & Data Foundation. I have personally joined the Kedro community slack channel and made some minor contributions to the codebase. The community is comprised of friendly and extremely talented individuals, many of whom are associated with QuantumBlack.
Insights of Kedro open-source:


Step 3 — Model Experiment Tracking and Management
The topic of model and experimental tacking has gained significant attention in recent years, with the emergence of various tools such as MLflow, TensorBoard to Neptune and Weight & Bias. Among these, Weight & Biases stands out for its seamless integration with popular machine learning frameworks such as Hugging Face, Yolo Analytics as well as its user-friendly interface design.
- Experiment tracking: Weights & Biases allows users to track and compare different experiments, including their parameters, metrics, and results.
- Model visualization: Users can visualize their models, including the architecture and weights, in a user-friendly interface.
- Automatic logging: Weights & Biases automatically logs all training and validation metrics, making it easy to track progress over time.
- Collaboration: Users can share their experiments and results with others, making it easy to collaborate on projects.
- Multi-language support: Weights & Biases supports multiple programming languages, including Python, R, and Java.
- Cloud-based: Weights & Biases is a cloud-based platform, which means users can access their experiments and results from anywhere.
- Alerts and notifications: Users can set up alerts and notifications to notify them when specific conditions are met, such as when a model reaches a certain accuracy threshold.
- Audit history: Users can view an audit history of all experiments, including when they were run, who ran them, and what changes were made.
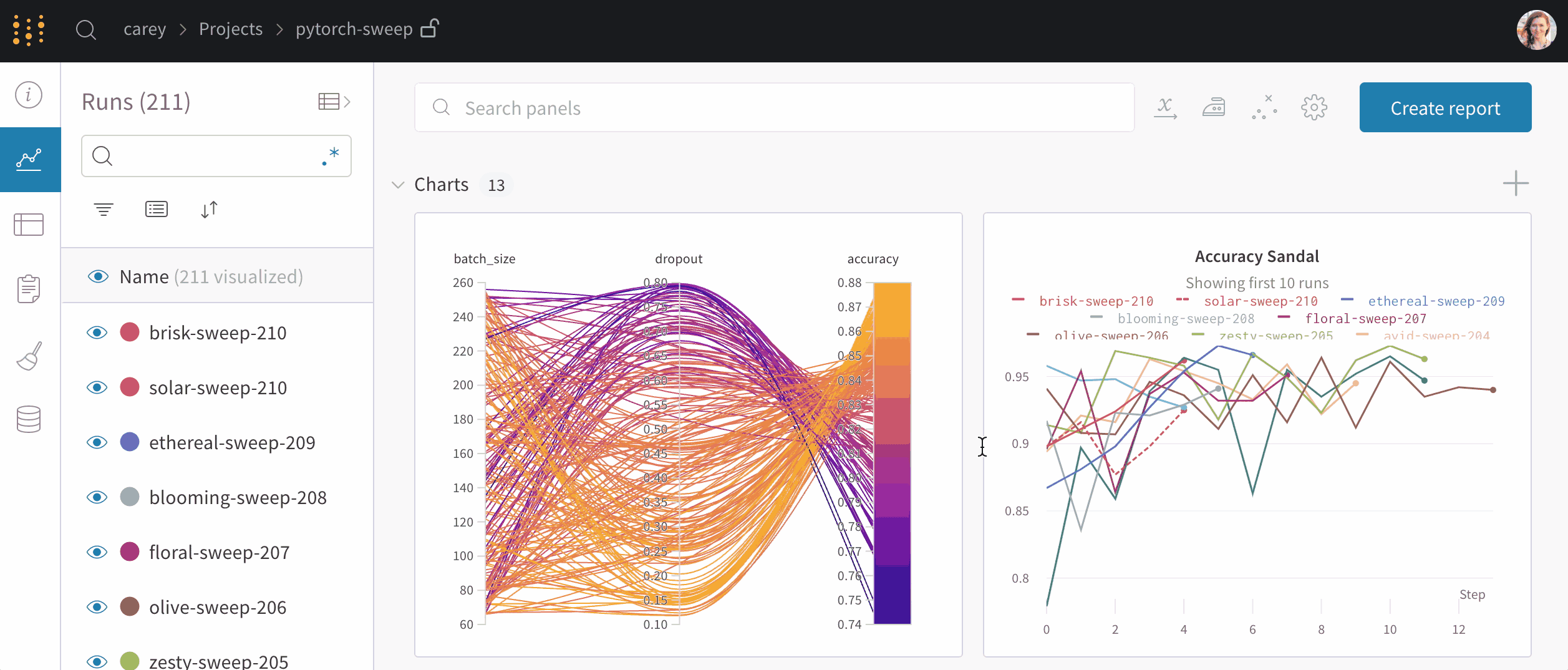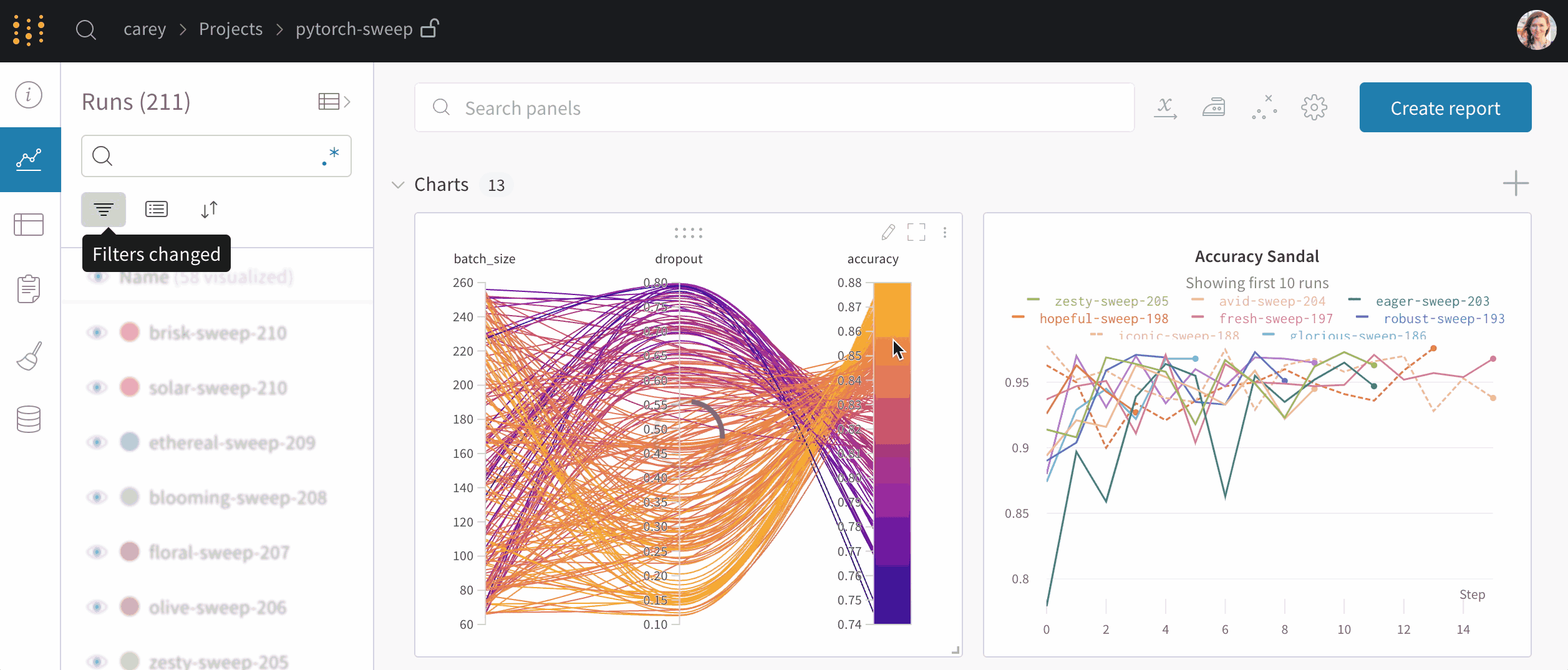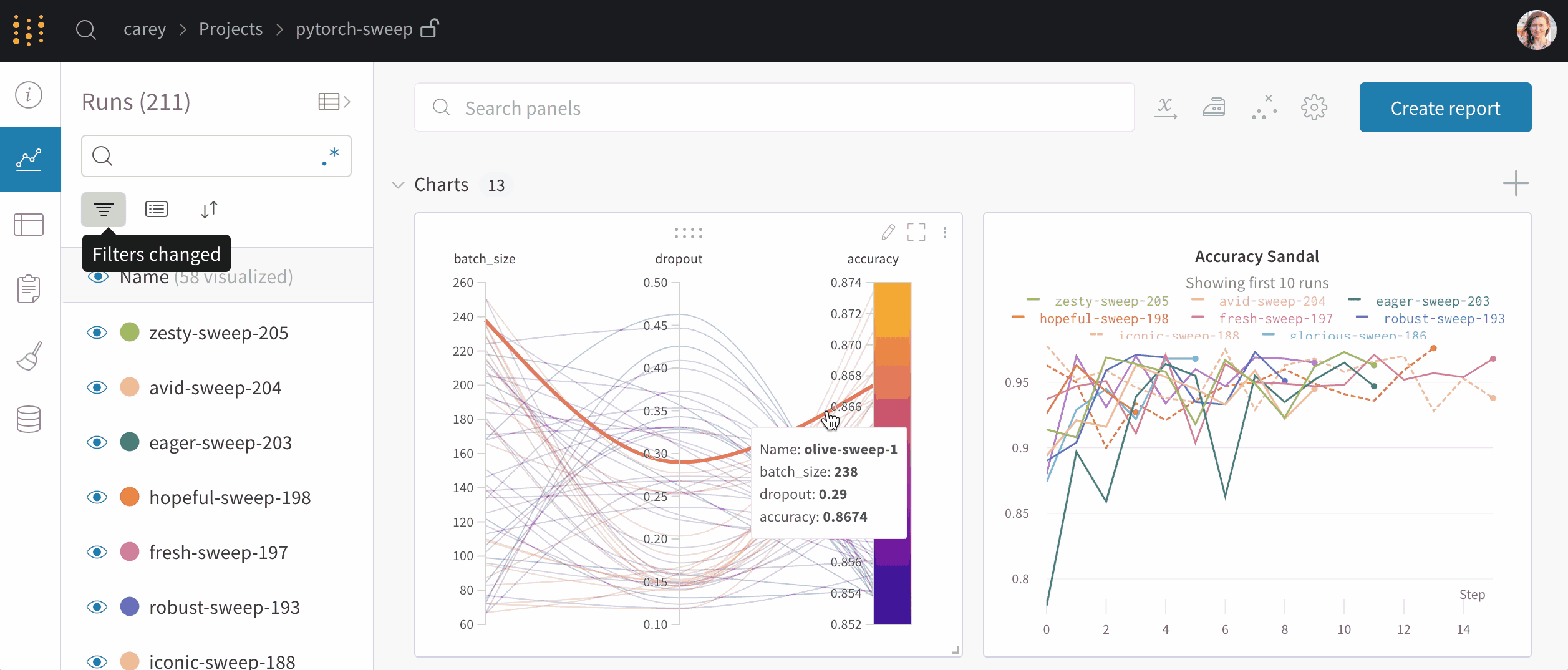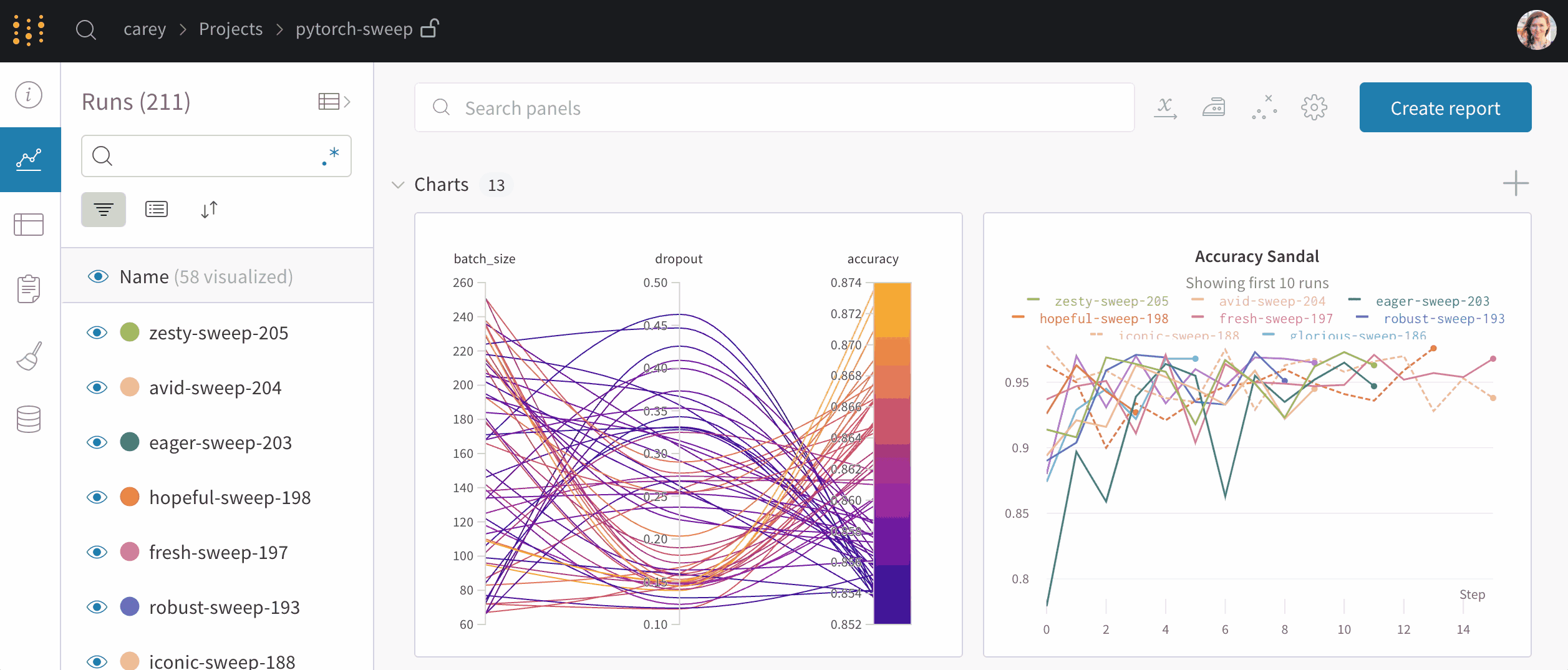
Insights of wandb open-source:


Summary:
Thanks for reading and hope you enjoyed it. This post presents a simplified MLOPs integration from an end-to-end ML flow perspective that can be implemented in three steps:
- Integrating with DBT core to govern and manage data transformation and lineage. Garbage in, garbage out, the success of ML projects is heavily dependent on the proper management of high-quality data.
- Developing production-ready DS/ML code based on the principles of modularity, scalability, and testability. Kedro framework is a great starting point.
- Integrating Weights & Biases cloud to track each training or experiment. Weights & Biases is seamlessly integrated with Hugging face and only requires three lines of code.
With DBT Core, Kedro, and Weights & Biases
I recently engaged in a project involving the implementation of a multiclass classification prediction system utilising financial transactional data, comprising over 10 million records and over 70 classes.
Through this project, I constructed a streamlined end-to-end machine learning operations (MLOPs) infrastructure that is well-suited for this specific use case, while maintaining cost efficiency.
The term MLOPs has a broad range of concepts and definitions, as offered by various vendors or solutions. Some focus on aspects such as training traceability and experimental tracking, while others prioritise feature storage or model deployment. In my understanding, MLOPs is the entire end-to-end process, from data extraction to model deployment and monitoring. However, not all components may be necessary for each use case, and the selection should be based on budget, requirements, and the organisation’s technology maturity.
Let’s walk through the logic of the implementation below.
The starting point, the source of my pain:
As is common with Data Science initiatives, the project initiation utilised Jupyter Notebook (SageMaker Studio in this case) as the primary tool for model development.
- The data was extracted directly from Athena based on tables/views followed by multiple data transformations. There is no direct version control for scripts and no virtualisation for data lineage, code is copied between UAT/Product environment for data extraction.
- Hugging Face Transformers has been integrated to provide access to pre-trained models, and the whole pre-processing features of engineering, training and evaluation are managed within the notebook.
The above process presents significant challenges for those responsible for maintaining it in a production setting, both from a data engineering or machine learning perspective. This includes challenges with troubleshooting, debugging, collaboration on the notebook, and refactoring code within the notebook…the list goes on.
Step 1 — Adding Data Extraction & Transformation Governance
AWS Athena is a robust and efficient serverless service that is designed mainly for ad-hoc SQL query tasks. However, its primary focus on ad-hoc tasks can make it challenging to maintain data lineage and transformation.
While building a dedicated data warehouse may not be cost-effective in this scenario, Athena offers a balance of computation power and cost. To fully leverage Athena’s capabilities and streamline the data extraction process, we need a tool on top of Athena to provide structured data management & processing.
DBT (DBT Core is open source) presents a viable solution for this case. Utilising a well-maintained Athena-Dbt Adapter, data can be probably traced and managed with the various features provided by DBT:
- Data integration: DBT allows for the integration of data from various sources, such as databases, spreadsheets, and APIs, into a single location for analysis and reporting.
- Data modelling: DBT allows users to create and modify data models, including the ability to create relationships between tables and define business logic.
- Data validation: DBT includes built-in validation checks to ensure data integrity and accuracy.
- Data lineage: DBT tracks the lineage of data and allows users to trace data back to its source, providing transparency and accountability.
- Automated testing: DBT includes automated testing capabilities, allowing users to test data models and ensure they are functioning as expected.
- Scheduling and monitoring: DBT allows for the scheduling and monitoring of data pipelines, including the ability to set up alerts and notifications for any issues or errors.
- Documenting and sharing: DBT includes the ability to document and share data models, making it easy for others to understand and use the data.
DBT is a widely adopted open-source tool in the Data Engineering domain and is utilised by many leading companies. As a data engineer, it is essential to have a familiarity with DBT or at least its underlying principles.
Insights of DBT core open-source:
Note: For a detailed explanation of the Athena+DBT integration, please refer to my previous post.
Step 2- Productionalize ML code
After adding DBT to govern the data extraction & transformation phase, the next step is to look into Jupyter Notebook.
Common issues when developing DS/ML code in Jupyter Notebooks include:
- Keeping track of code and output: Jupyter notebooks can become cluttered with code and output, making it difficult to keep track of what has been done and what the current state of the model is.
- Reproducibility: Jupyter notebooks are not always easy to share or reproduce, as they can contain hidden states or other dependencies that are not obvious from the code.
- Debugging: Debugging machine learning code can be difficult in Jupyter notebooks, as the code is often spread across multiple cells and it can be hard to see the entire state of the system at any given time.
- Version control: Jupyter notebooks are not well-suited for version control, as the output and other metadata are stored in the notebook file itself, making it hard to diff or merge changes.
- Dependency management: Jupyter notebooks can make it difficult to manage dependencies and ensure that the code runs on different machines or in different environments.
- No integrated auto-testing capability
The Jupyter Notebook is not equipped for production readiness and can prove costly for organisations that need to hire MLE to productionlise code from it.
Kedro offers a solution to this challenge by providing an open-source Python framework that facilitates the creation of reproducible, maintainable, and modular data science code. It incorporates software engineering best practices to enable the development of production-ready data science pipelines.
Code is developed in the Kedro framework and can be deployed to SageMaker Studio (this is only one of many supported deployments) for enhanced computing power like GPU.
Kedro was initially developed by QuantumBlack, AI by Mckinsey and is now hosted by the LF AI & Data Foundation. I have personally joined the Kedro community slack channel and made some minor contributions to the codebase. The community is comprised of friendly and extremely talented individuals, many of whom are associated with QuantumBlack.
Insights of Kedro open-source:
Step 3 — Model Experiment Tracking and Management
The topic of model and experimental tacking has gained significant attention in recent years, with the emergence of various tools such as MLflow, TensorBoard to Neptune and Weight & Bias. Among these, Weight & Biases stands out for its seamless integration with popular machine learning frameworks such as Hugging Face, Yolo Analytics as well as its user-friendly interface design.
- Experiment tracking: Weights & Biases allows users to track and compare different experiments, including their parameters, metrics, and results.
- Model visualization: Users can visualize their models, including the architecture and weights, in a user-friendly interface.
- Automatic logging: Weights & Biases automatically logs all training and validation metrics, making it easy to track progress over time.
- Collaboration: Users can share their experiments and results with others, making it easy to collaborate on projects.
- Multi-language support: Weights & Biases supports multiple programming languages, including Python, R, and Java.
- Cloud-based: Weights & Biases is a cloud-based platform, which means users can access their experiments and results from anywhere.
- Alerts and notifications: Users can set up alerts and notifications to notify them when specific conditions are met, such as when a model reaches a certain accuracy threshold.
- Audit history: Users can view an audit history of all experiments, including when they were run, who ran them, and what changes were made.
Insights of wandb open-source:
Summary:
Thanks for reading and hope you enjoyed it. This post presents a simplified MLOPs integration from an end-to-end ML flow perspective that can be implemented in three steps:
- Integrating with DBT core to govern and manage data transformation and lineage. Garbage in, garbage out, the success of ML projects is heavily dependent on the proper management of high-quality data.
- Developing production-ready DS/ML code based on the principles of modularity, scalability, and testability. Kedro framework is a great starting point.
- Integrating Weights & Biases cloud to track each training or experiment. Weights & Biases is seamlessly integrated with Hugging face and only requires three lines of code.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.