
Extracting Keywords From Text – DZone
If your work involves data analysis, SEO optimization, or any role that requires sifting through digital content, understanding how to effectively extract keywords is essential. This skill streamlines data management and accessibility, representing a significant advancement in data processing and analysis methodologies.
Right at the center of this ability is Natural Language Processing. This cutting-edge technology empowers computers to understand human language, effectively narrowing the divide between digital data management and actual human interaction. Within this domain, the spaCy Python library stands out for its robust language processing features. Known for its efficiency and ease of use, spaCy empowers professionals across various fields to enhance their text analysis practices, improving their workflows and outcomes.
With this article, I would like to help you broaden your understanding of NLP and show how spaCy can be your powerful ally in effective keyword extraction. By exploring these technologies, you will be equipped with the knowledge to leverage their potential, boosting your ability to extract valuable information from text.
Understanding Natural Language Processing
NLP is an essential field within the broader AI discipline that bridges human communication and computer understanding. It’s the technology behind the computer’s ability to interpret, understand, and derive meaning from human language. NLP blends the structured approach of computational linguistics with the innovative techniques of statistical methods, machine learning, and deep learning.
NLP is a constant presence in our lives, subtly powering things like voice-activated GPS and our smartphones’ virtual assistants. et, NLP’s role extends far beyond simple commands; it delves into complex areas like text analysis, translating languages, assessing sentiments, and importantly for our discussion, extracting keywords.
The process of keyword extraction involves the identification of the most relevant words or phrases within a text. These keywords can summarise the content and offer insights at a glance about the subject matter discussed. This technique is crucial for professionals who need to process and categorize large amounts of text efficiently. By utilizing NLP to automate keyword extraction, significant time savings can be achieved. This reduction in manual effort allows professionals to dedicate more time to analysis and decision-making, streamlining the data preprocessing stage.
Introduction to spaCy
spaCy is a critical instrument in the toolkit of professionals working with NLP. Its design caters to those requiring efficient and accurate language processing capabilities, making it a cornerstone for projects involving text analysis. Built on Python, spaCy combines simplicity with power, offering functionalities that cover a broad spectrum of NLP tasks including tokenization, part-of-speech tagging, named entity recognition, and dependency parsing.
What sets spaCy apart is its commitment to performance and scalability. Optimized for speed, it processes large volumes of text swiftly, ensuring projects that involve extensive datasets or real-time data streams benefit from reduced processing times. spaCy’s algorithms are adept at capturing the subtleties of human language, thus enhancing the relevance and depth of keyword extraction outcomes.
spaCy boasts comprehensive documentation and the support of a vibrant community, offering an easy start. These resources facilitate a smooth integration of spaCy into various projects, whether for enhancing existing workflows or embedding NLP capabilities into new applications. Below, we will delve into spaCy’s installation, explore its model architecture, and illustrate its application in keyword extraction through practical examples.
Installing spaCy and Setting up Your Environment
To begin leveraging spaCy for your NLP tasks, the first step involves setting up spaCy on your machine. This process is quite straightforward:
1. Prerequisites
spaCy supports various Python versions, making it accessible to most users. For a seamless experience, I recommend using a virtual environment to manage dependencies effectively.
2. Install spaCy
Execute the following command in your terminal or command prompt:
pip install -U pip setuptools wheel
pip install -U spacy3. Download Language Models
spaCy operates using language models tailored to different languages. These models play a key role in tasks like tokenization, part-of-speech tagging, and named entity recognition. To download a model, use:
python -m spacy download en_core_web_lgIn general, spaCy expects all pipeline packages to follow the naming convention of [lang]_[name].
For spaCy’s pipelines, we also chose to divide the name into three components:
- Type: Capabilities (e.g. core for a general-purpose pipeline with tagging, parsing, lemmatization, and named entity recognition, or dep for only tagging, parsing, and lemmatization).
- Genre: Type of text the pipeline is trained on, e.g. web or news.
- Size: Package size indicator, sm, md, lg or trf. For pipelines with default vectors, md has a reduced word vector table with 20k unique vectors for ~500k words and lg has a large word vector table with ~500k entries. For pipelines with floret vectors, md vector tables have 50k entries and lg vector tables have 200k entries.
e.g., en_core_web_sm is a small English pipeline trained on written web text (blogs, news, comments), that includes vocabulary, syntax, and entities. spaCy offers models of different sizes to balance between speed and accuracy according to your project needs.
With spaCy installed, integrating it into your projects involves but a few lines of code. The library’s design emphasizes ease of use, allowing you to focus on the application logic rather than boilerplate code.
Practical Applications of spaCy for Keyword Extraction
spaCy, with its comprehensive NLP capabilities, excels at extracting keywords efficiently, especially when leveraging its larger models like en_core_web_lg for enhanced accuracy.
Consider a scenario where we analyze a sports news article to extract key entities such as names of athletes, locations, and important numbers. Let’s apply spaCy to a text snapshot from an article discussing Andy Murray’s career:
import spacy
import pandas as pd
# Load spaCy's large English model
nlp = spacy.load("en_core_web_lg")
# Sample text from a sports news article
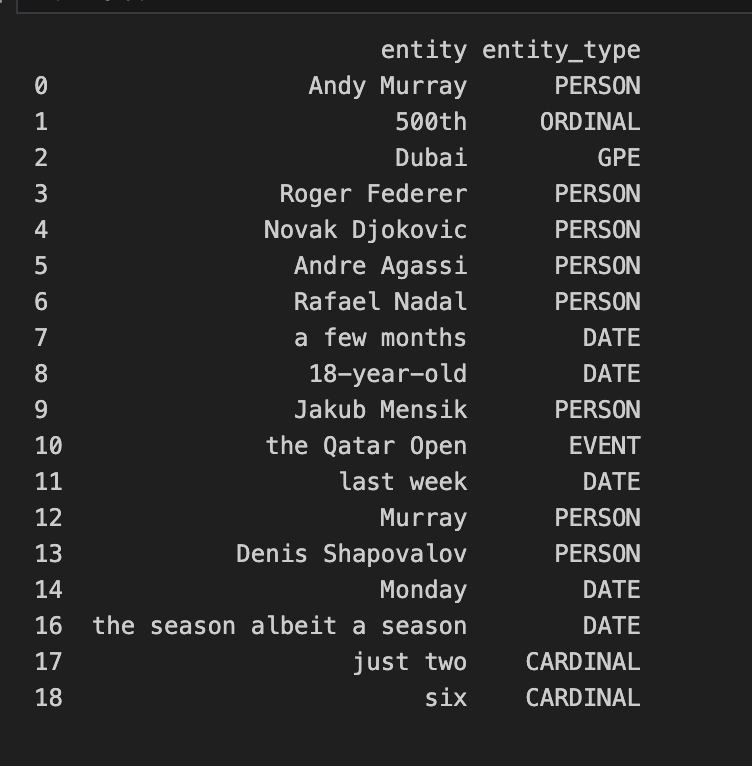
text = """Andy Murray chalked up a 500th hard-court win in Dubai to join an exclusive club containing greats Roger Federer, Novak Djokovic, Andre Agassi, and Rafael Nadal - then sparked more speculation over his future by suggesting he only has a few months left of his career. Fresh from a chastening defeat to 18-year-old Jakub Mensik in the Qatar Open last week, Murray produced a superb comeback to beat Denis Shapovalov on Monday. It was Murray's biggest result of the season - albeit a season that has yielded just two wins from six tournaments."""
# Process the text with spaCy
doc = nlp(text)
# Extract entities and their labels
ent_label = []
for ent in doc.ents:
ent_label.append([ent.text, ent.label_])
# Create a DataFrame to display entities and their types
df = pd.DataFrame(ent_label, columns=['entity', 'entity_type']).drop_duplicates()
print(df)This code snippet processes the text, identifying and labeling entities such as personal names, organizations, locations, and numbers. By converting these entities into a pandas DataFrame, we can easily view and analyze the extracted information.
Beyond Basic Extraction
While the example above focuses on extracting named entities, spaCy’s capabilities extend further. By customizing the NLP pipeline or integrating spaCy with machine learning models, you can refine the keyword extraction process to suit specific needs. This might involve identifying thematic keywords beyond named entities, sentiment analysis to gauge the text’s tone, or linking extracted keywords to broader topics for comprehensive content analysis.
In practice, leveraging spaCy for keyword extraction empowers professionals to navigate and organize large datasets effectively. Whether summarising news articles, analyzing customer feedback, or categorizing research papers, spaCy provides a scalable and accurate solution to extract meaningful keywords.
Challenges and Limitations of spaCy
Despite spaCy’s robust capabilities in keyword extraction and NLP tasks, you may encounter challenges and limitations that stem from the inherent complexities of language and the tool’s design. One significant challenge is handling nuanced or ambiguous language. Natural language is filled with complexities, such as idioms, sarcasm, and meanings that depend on the context. Despite spaCy’s models being trained on large datasets to recognize a variety of linguistic patterns, they sometimes struggle to interpret texts with a high degree of ambiguity or specialized terminology. This issue can affect the accuracy of keyword extraction, potentially leading to the model missing or incorrectly interpreting important information.
spaCy’s effectiveness and precision rely a lot on the quality and relevance of its pre-trained models. While these models are a powerful starting point, their effectiveness can vary across different languages and specialized domains. For instance, a model trained primarily on news articles might struggle to accurately process technical documents from fields like law or medicine. This means you’ll have to put in extra work to custom-train or tweak the models with data that’s specific to your field. Yet, even with these hurdles, spaCy stands out as a go-to for NLP tasks. Knowing where it falls short is key to making the most of what it offers and sidestepping any issues.
spaCy shines in the domain of Natural Language Processing, packing a suite of features for different text analysis tasks, keyword extraction included. Its setup strikes a neat balance between being fast and handling language with a thorough touch, giving folks in all sorts of jobs a serious boost in working through loads of text data to find the nuggets of insight they need. The ability to swiftly and accurately extract keywords using spaCy not only streamlines data management but also significantly boosts the analytical processes, enabling a deeper understanding of the content at scale.
In our exploration of spaCy and its application in extracting keywords, we’ve unveiled the layers of its functionality and practicality, aiming to equip you with the knowledge to leverage this powerful library. As you integrate spaCy into your NLP tasks, remember that the journey of discovery and optimization in digital text analysis is ongoing. Embrace the challenges, celebrate the insights, and continue to innovate, ensuring that your work remains at the cutting edge of technology’s capabilities.
If your work involves data analysis, SEO optimization, or any role that requires sifting through digital content, understanding how to effectively extract keywords is essential. This skill streamlines data management and accessibility, representing a significant advancement in data processing and analysis methodologies.
Right at the center of this ability is Natural Language Processing. This cutting-edge technology empowers computers to understand human language, effectively narrowing the divide between digital data management and actual human interaction. Within this domain, the spaCy Python library stands out for its robust language processing features. Known for its efficiency and ease of use, spaCy empowers professionals across various fields to enhance their text analysis practices, improving their workflows and outcomes.
With this article, I would like to help you broaden your understanding of NLP and show how spaCy can be your powerful ally in effective keyword extraction. By exploring these technologies, you will be equipped with the knowledge to leverage their potential, boosting your ability to extract valuable information from text.
Understanding Natural Language Processing
NLP is an essential field within the broader AI discipline that bridges human communication and computer understanding. It’s the technology behind the computer’s ability to interpret, understand, and derive meaning from human language. NLP blends the structured approach of computational linguistics with the innovative techniques of statistical methods, machine learning, and deep learning.
NLP is a constant presence in our lives, subtly powering things like voice-activated GPS and our smartphones’ virtual assistants. et, NLP’s role extends far beyond simple commands; it delves into complex areas like text analysis, translating languages, assessing sentiments, and importantly for our discussion, extracting keywords.
The process of keyword extraction involves the identification of the most relevant words or phrases within a text. These keywords can summarise the content and offer insights at a glance about the subject matter discussed. This technique is crucial for professionals who need to process and categorize large amounts of text efficiently. By utilizing NLP to automate keyword extraction, significant time savings can be achieved. This reduction in manual effort allows professionals to dedicate more time to analysis and decision-making, streamlining the data preprocessing stage.
Introduction to spaCy
spaCy is a critical instrument in the toolkit of professionals working with NLP. Its design caters to those requiring efficient and accurate language processing capabilities, making it a cornerstone for projects involving text analysis. Built on Python, spaCy combines simplicity with power, offering functionalities that cover a broad spectrum of NLP tasks including tokenization, part-of-speech tagging, named entity recognition, and dependency parsing.
What sets spaCy apart is its commitment to performance and scalability. Optimized for speed, it processes large volumes of text swiftly, ensuring projects that involve extensive datasets or real-time data streams benefit from reduced processing times. spaCy’s algorithms are adept at capturing the subtleties of human language, thus enhancing the relevance and depth of keyword extraction outcomes.
spaCy boasts comprehensive documentation and the support of a vibrant community, offering an easy start. These resources facilitate a smooth integration of spaCy into various projects, whether for enhancing existing workflows or embedding NLP capabilities into new applications. Below, we will delve into spaCy’s installation, explore its model architecture, and illustrate its application in keyword extraction through practical examples.
Installing spaCy and Setting up Your Environment
To begin leveraging spaCy for your NLP tasks, the first step involves setting up spaCy on your machine. This process is quite straightforward:
1. Prerequisites
spaCy supports various Python versions, making it accessible to most users. For a seamless experience, I recommend using a virtual environment to manage dependencies effectively.
2. Install spaCy
Execute the following command in your terminal or command prompt:
pip install -U pip setuptools wheel
pip install -U spacy3. Download Language Models
spaCy operates using language models tailored to different languages. These models play a key role in tasks like tokenization, part-of-speech tagging, and named entity recognition. To download a model, use:
python -m spacy download en_core_web_lgIn general, spaCy expects all pipeline packages to follow the naming convention of [lang]_[name].
For spaCy’s pipelines, we also chose to divide the name into three components:
- Type: Capabilities (e.g. core for a general-purpose pipeline with tagging, parsing, lemmatization, and named entity recognition, or dep for only tagging, parsing, and lemmatization).
- Genre: Type of text the pipeline is trained on, e.g. web or news.
- Size: Package size indicator, sm, md, lg or trf. For pipelines with default vectors, md has a reduced word vector table with 20k unique vectors for ~500k words and lg has a large word vector table with ~500k entries. For pipelines with floret vectors, md vector tables have 50k entries and lg vector tables have 200k entries.
e.g., en_core_web_sm is a small English pipeline trained on written web text (blogs, news, comments), that includes vocabulary, syntax, and entities. spaCy offers models of different sizes to balance between speed and accuracy according to your project needs.
With spaCy installed, integrating it into your projects involves but a few lines of code. The library’s design emphasizes ease of use, allowing you to focus on the application logic rather than boilerplate code.
Practical Applications of spaCy for Keyword Extraction
spaCy, with its comprehensive NLP capabilities, excels at extracting keywords efficiently, especially when leveraging its larger models like en_core_web_lg for enhanced accuracy.
Consider a scenario where we analyze a sports news article to extract key entities such as names of athletes, locations, and important numbers. Let’s apply spaCy to a text snapshot from an article discussing Andy Murray’s career:
import spacy
import pandas as pd
# Load spaCy's large English model
nlp = spacy.load("en_core_web_lg")
# Sample text from a sports news article
text = """Andy Murray chalked up a 500th hard-court win in Dubai to join an exclusive club containing greats Roger Federer, Novak Djokovic, Andre Agassi, and Rafael Nadal - then sparked more speculation over his future by suggesting he only has a few months left of his career. Fresh from a chastening defeat to 18-year-old Jakub Mensik in the Qatar Open last week, Murray produced a superb comeback to beat Denis Shapovalov on Monday. It was Murray's biggest result of the season - albeit a season that has yielded just two wins from six tournaments."""
# Process the text with spaCy
doc = nlp(text)
# Extract entities and their labels
ent_label = []
for ent in doc.ents:
ent_label.append([ent.text, ent.label_])
# Create a DataFrame to display entities and their types
df = pd.DataFrame(ent_label, columns=['entity', 'entity_type']).drop_duplicates()
print(df)This code snippet processes the text, identifying and labeling entities such as personal names, organizations, locations, and numbers. By converting these entities into a pandas DataFrame, we can easily view and analyze the extracted information.
![extracted information]()
Beyond Basic Extraction
While the example above focuses on extracting named entities, spaCy’s capabilities extend further. By customizing the NLP pipeline or integrating spaCy with machine learning models, you can refine the keyword extraction process to suit specific needs. This might involve identifying thematic keywords beyond named entities, sentiment analysis to gauge the text’s tone, or linking extracted keywords to broader topics for comprehensive content analysis.
In practice, leveraging spaCy for keyword extraction empowers professionals to navigate and organize large datasets effectively. Whether summarising news articles, analyzing customer feedback, or categorizing research papers, spaCy provides a scalable and accurate solution to extract meaningful keywords.
Challenges and Limitations of spaCy
Despite spaCy’s robust capabilities in keyword extraction and NLP tasks, you may encounter challenges and limitations that stem from the inherent complexities of language and the tool’s design. One significant challenge is handling nuanced or ambiguous language. Natural language is filled with complexities, such as idioms, sarcasm, and meanings that depend on the context. Despite spaCy’s models being trained on large datasets to recognize a variety of linguistic patterns, they sometimes struggle to interpret texts with a high degree of ambiguity or specialized terminology. This issue can affect the accuracy of keyword extraction, potentially leading to the model missing or incorrectly interpreting important information.
spaCy’s effectiveness and precision rely a lot on the quality and relevance of its pre-trained models. While these models are a powerful starting point, their effectiveness can vary across different languages and specialized domains. For instance, a model trained primarily on news articles might struggle to accurately process technical documents from fields like law or medicine. This means you’ll have to put in extra work to custom-train or tweak the models with data that’s specific to your field. Yet, even with these hurdles, spaCy stands out as a go-to for NLP tasks. Knowing where it falls short is key to making the most of what it offers and sidestepping any issues.
spaCy shines in the domain of Natural Language Processing, packing a suite of features for different text analysis tasks, keyword extraction included. Its setup strikes a neat balance between being fast and handling language with a thorough touch, giving folks in all sorts of jobs a serious boost in working through loads of text data to find the nuggets of insight they need. The ability to swiftly and accurately extract keywords using spaCy not only streamlines data management but also significantly boosts the analytical processes, enabling a deeper understanding of the content at scale.
In our exploration of spaCy and its application in extracting keywords, we’ve unveiled the layers of its functionality and practicality, aiming to equip you with the knowledge to leverage this powerful library. As you integrate spaCy into your NLP tasks, remember that the journey of discovery and optimization in digital text analysis is ongoing. Embrace the challenges, celebrate the insights, and continue to innovate, ensuring that your work remains at the cutting edge of technology’s capabilities.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.