
Maximizing the Potential of LLMs
LLMs do Natural Language Processing (NLP) to represent the meaning of the text as a vector. This representation of the words of the text is an embedding.
The Token Limit: The LLM Prompting Biggest Problem
Currently, one of the biggest problems with LLM prompting is the token limit. When GPT-3 was released, the limit for both the prompt and the output combined was 2,048 tokens. With GPT-3.5, this limit increased to 4,096 tokens. Now, GPT-4 comes in two variants. One with a limit of 8,192 tokens and another with a limit of 32,768 tokens, around 50 pages of text.
So, what can you do when you might want to do a prompt with a context larger than this limit? Of course, the only solution is to make the context shorter. But how can you make it shorter and at the same time have all the relevant information? The solution: store the context in a vector database and find the relevant context with a similarity search query.
What Are Vector Embeddings?
Let’s start by explaining what vector embeddings are. Roy Keynes’ definition is: “Embeddings are learned transformations to make data more useful.” A neural network learns to transform the text into a vector space that contains its actual meaning. This is more useful because it can find synonyms and the syntactical and semantical relationships between words. This visual helps us understand how those vectors can encode meaning:
What Do Vector Databases Do?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
Similarity Search
We can find the similarity of vectors by calculating a vector’s distance from all other vectors. The nearest neighbors will be the most similar results to the query vector. This is how flat indexes in vector databases work. But this is not very efficient; in a large database, this might take a very long time.
To improve the search’s performance, we can try to calculate the distance for only a subset of the vectors. This approach, called approximate nearest neighbors (ANN), improves speed but sacrifices the quality of results. Some popular ANN indexes are Locally Sensitive Hashing (LSH), Hierarchical Navigable Small Worlds (HNSW), or Inverted File Index (IVF).
Integrating Vector Stores and LLMs
For this example, I downloaded the whole Numpy documentation (with over 2000 pages) as a PDF from this URL.
We can write Python code to transform the context document into embeddings and save them to a vector store. We will use LangChain to load the document and split it into chunks and Faiss (Facebook AI Similarity Search) as a vector database.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")Now, we can use this database to perform a similarity search query to find pages that might be related to our prompt. Then, we use the resulting chunks to fill the context of our prompt. We will use LangChain to make it easier:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)Our question for the model is, “How to calculate the median of an array.” Even though the context that we give it is way over the token limit, we have overcome this limitation and got an answer:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".This is just one clever solution for a very new problem. As LLMs keep evolving, maybe problems like this will be solved without the need for these kinds of clever solutions. However, I’m sure that this evolution will open the door for new capabilities that might need other new clever solutions for the challenges that they may bring.
LLMs do Natural Language Processing (NLP) to represent the meaning of the text as a vector. This representation of the words of the text is an embedding.
The Token Limit: The LLM Prompting Biggest Problem
Currently, one of the biggest problems with LLM prompting is the token limit. When GPT-3 was released, the limit for both the prompt and the output combined was 2,048 tokens. With GPT-3.5, this limit increased to 4,096 tokens. Now, GPT-4 comes in two variants. One with a limit of 8,192 tokens and another with a limit of 32,768 tokens, around 50 pages of text.
So, what can you do when you might want to do a prompt with a context larger than this limit? Of course, the only solution is to make the context shorter. But how can you make it shorter and at the same time have all the relevant information? The solution: store the context in a vector database and find the relevant context with a similarity search query.
What Are Vector Embeddings?
Let’s start by explaining what vector embeddings are. Roy Keynes’ definition is: “Embeddings are learned transformations to make data more useful.” A neural network learns to transform the text into a vector space that contains its actual meaning. This is more useful because it can find synonyms and the syntactical and semantical relationships between words. This visual helps us understand how those vectors can encode meaning:
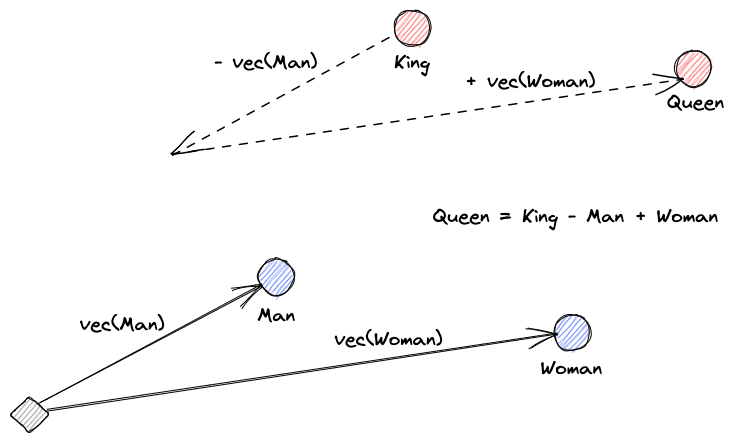
What Do Vector Databases Do?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
Similarity Search
We can find the similarity of vectors by calculating a vector’s distance from all other vectors. The nearest neighbors will be the most similar results to the query vector. This is how flat indexes in vector databases work. But this is not very efficient; in a large database, this might take a very long time.
To improve the search’s performance, we can try to calculate the distance for only a subset of the vectors. This approach, called approximate nearest neighbors (ANN), improves speed but sacrifices the quality of results. Some popular ANN indexes are Locally Sensitive Hashing (LSH), Hierarchical Navigable Small Worlds (HNSW), or Inverted File Index (IVF).
Integrating Vector Stores and LLMs
For this example, I downloaded the whole Numpy documentation (with over 2000 pages) as a PDF from this URL.
We can write Python code to transform the context document into embeddings and save them to a vector store. We will use LangChain to load the document and split it into chunks and Faiss (Facebook AI Similarity Search) as a vector database.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")Now, we can use this database to perform a similarity search query to find pages that might be related to our prompt. Then, we use the resulting chunks to fill the context of our prompt. We will use LangChain to make it easier:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)Our question for the model is, “How to calculate the median of an array.” Even though the context that we give it is way over the token limit, we have overcome this limitation and got an answer:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".This is just one clever solution for a very new problem. As LLMs keep evolving, maybe problems like this will be solved without the need for these kinds of clever solutions. However, I’m sure that this evolution will open the door for new capabilities that might need other new clever solutions for the challenges that they may bring.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.