
ML Prediction on Streaming Data Using Kafka Streams | by Alon Agmon | Jul, 2022
Boost the performance of your Python-trained ML models by serving them over your Kafka streaming platform in a Scala application
Suppose you have a robust streaming platform based on Kafka, which cleans and enriches your customers’ event data before writing it to some warehouse. One day, during a casual planning meeting, your product manager raises the requirement to use a machine learning model (developed by the data science team) over incoming data and generate an alert for messages marked by the model. “No problem”, you reply. “We can select any data set we want from the data warehouse, and then run whatever model we want”. “Not exactly”, the PM replies. “We want this to run as real-time as possible. We want the results of the ML model to be available for consumption in a Kafka topic in less than a minute after we receive the event”.
This is a common requirement, and it will only get more popular. The requirement for real time ML inference on streaming data becomes important for many customers that have to make time-sensitive decisions on the result of the model.
It seems that big data engineering and data science play nicely together and should have some straightforward solution, but often that is not the case, and using ML for near real time inference over heavy workloads of data involves quite a few challenges. Among these challenges, for example, is the difference between Python, which is the dominant language of ML, and the JVM environment (Java/Scala) which is the dominant environment for big data engineering and data streaming. Another challenge relates to the data platform we are using for our workloads. If you are already working with Spark then you have the Spark ML lib at your service, but sometimes it will not be good enough, and sometimes (as in our case) Spark is not part of our stack or infra.
Its true that the ecosystem is aware of these challenges and is slowly addressing them with new features, though our specific and common scenario currently leaves you with a few common options. One, for example, is to add Spark to your stack and write a pySpark job that will add the ML inference stage to your pipeline. This is will offer better support for Python for your data science team but it also means that your data processing flow might take longer and that you also need to add and maintain a Spark cluster to your stack. Another option would be to use some third-party model serving platform that will expose an inference service endpoint based on your model. This might help you retain your performance but might also require the cost of additional infra while being an overkill for the some tasks.
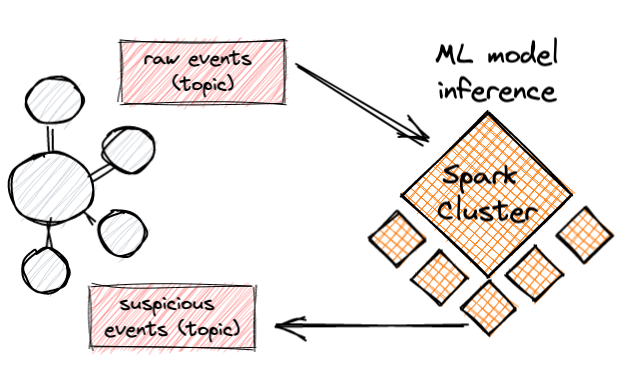
In this post, I want to show another approach to this task using Kafka Streams. The advantage of using Kafka Streams for this task is that unlike Flink or Spark, it does not require a dedicated compute cluster. Rather, it can run on any application server or container environment you are already using, and if you are already using Kafka for stream processing, then it can be embedded in your flow quite seamlessly.
While both Spark and Flink have their machine learning libraries and tutorials, using Kafka Streams for this task seems like a less common use case , and my goal is to show how easy it is to implement. Specifically, I show how we can use an XGBoost model — a production grade machine learning model, trained in a Python environment, for real time inference over a stream of events on a Kafka topic.
This is intended to be a very hands-on post. In Section 2, we train an XGBoost classifier on a fraud detection dateset. We do so in a Jupyter notebook in a Python environment. Section 3 is an example for how the model’s binary can be imported and wrapped in a Scala class, and Section 4 shows how this can be embedded in a Kafka Stream application and generate real time prediction on streaming data. At the end of the post you can find a link to a repo with the full code described here.
( Note that in many cases I use Scala in a very non-idiomatic way. I do so for the sake of clarity as idiomatic Scala can sometimes be confusing. )
For this example, we start by training a simple classification model based on the Kaggle credit fraud data set.¹ You can find the full model training code here. The important bit (below) is that after we (or our data scientists) are satisfied with the results of our model, we simply save it in its simple binary form. This binary is all we need to load the model in our Kafka Streams app.
In this section we start implementing our Kafka Streams application by first wrapping our machine learning model in a Scala object (a singleton), which we will use to run inference on incoming records. This object will implement a predict() method that our stream processing application will use over each of the streaming events. The method will receive a record ID and an array of fields or features and will return a tuple that consists of the record id and the score the model gave it.
XGBoost model loading and prediction in Scala is pretty straightforward (though it should be noted that support in more recent Scala versions might be limited). After initial imports, we start by loading the *trained* model to a Booster variable.
Implementing the predict() method is also fairly simple. Each of our events contains an array of 10 features or fields that we will need to provide as input to our model.
The object type that XGboost uses to wrap the input vector for prediction is a DMatrix, which can be constructed in a number of ways. I will use the dense matrix format, which is based on providing a flat array of floats that represents the model features or fields; the length of each vector (nCols); and the numbers of vectors in the data set (nRows). For example, if our model is used to run inference on a vector with 10 features or fields, and we want to predict one vector at a time, then our DMatrix will be instantiated with an array of floats with length = 10, nCols = 10, and nRows = 1 (because there is only one vector in the set).
That will do the work for our Classifier object that wraps a trained XGboost ML model. There will be one Classifier object with a predict() method that will be called for each record.
Before we get into the code and details of our streaming application and show how we can use our Classifier on streaming data, its important to highlight the advantage and motivation of using Kafka Streams in such a system.
With Spark, just for example, distribution of compute is done by a cluster manager, that receives instructions from a driver application and distributes compute tasks to executors nodes in a dedicated cluster. Each Spark executor is responsible to process a set of partitions of the data. The power of Kafka Streams (KS) is that although it similarly achieves scale with parallelism — i.e., by running multiple replicas of the stream processing app, it does not depend on a dedicated cluster for that, but only on Kafka. In other words, the lifecycle of the compute nodes can be managed by any container orchestration system (such as K8S) or any other application server while leaving the coordination and management to Kafka (and the KS library). This may seem like a minor advantage, but this is exactly Spark’s greatest pain.
Indeed, unlike Spark, KS is a library that can be imported into any JVM-based application and, most importantly, run on any application infrastructure. A KS application typically reads streaming messages from a Kafka topic, performs its transformations, and writes the results to an output topic. State and stateful transformations, such as aggregations or windowed computations, are persisted and managed by Kafka, and scale is achieved by simply running more instances of your application (limited by the number of partitions the topic has and the consumer policy).
The basis of a KS app is a Topology, which defines the stream processing logic of the application or how input data is transformed into output data. In our case, the topology will run as follows
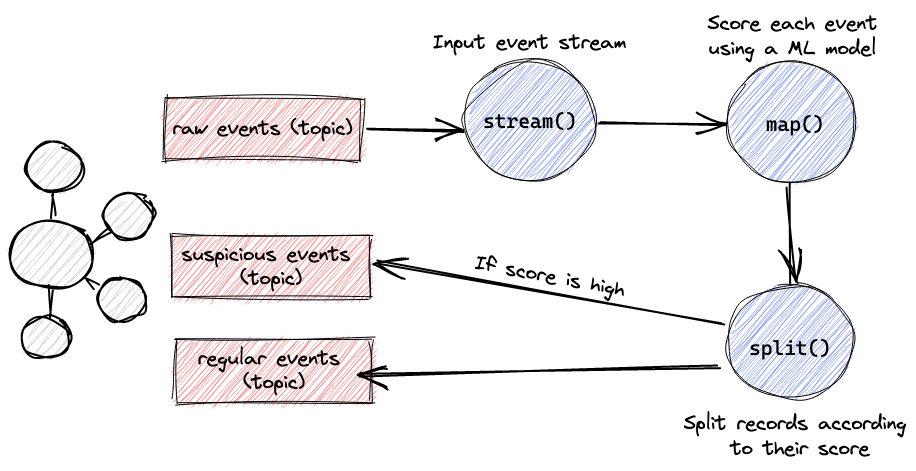
The topology here is fairly simple. It starts by reading streaming records from the input topic on Kafka, then it uses a map operation to run the model’s predict method on each record, and finally it splits the stream, and sends record ids that recived a high score from the model to a “suspicious events” output topic and the rest to another. Lets see how this looks in code.
Our starting point is the builder.stream method which starts reading messages from inputTopic topic on Kafka. I will shortly explain it more, but note that we are serializing each kafka record key as String and its payload as an object of type PredictRequest. PredictRequest is a Scala case class that corresponds to the protobuf schema below. This ensures that integration with message producers is straight forward but also makes is easier to generate the de/serialization methods that we are required to provide when dealing with custom objects.
message PredictRequest{
string recordID = 1;
repeated float featuresVector = 4;
}
Next, we use map() to call our classifier’s predict() method on the array that each message carries. Recall that this method returns a tuple of recordID and score, which is streamed back from the map operation. Finally, we use the split() method to create 2 branches of the stream — one for results higher than 0.5 and one for the others. We then send each branch of the stream to their own designated topic. Any consumer subsribed to the output topic will now recieve an alert for a suspicious record id (hopefully) near real time
One last comment on serialization:
Using custom classes or objects in a KS app written in Scala, either for the key or the value of the Kafka record, requires you to make available an implicit Serde[T] for the type (which includes its serializer and deserializer). Since I used a proto object as the message payload, much of the heavy lifting was done by scalapbc which “compiles” a proto schema to a Scala class that already contains the important methods to de/serialize the class. Making this implicit val available to the stream method (either in scope or by import ) enable this.
implicit val RequestSerde: Serde[PredictRequest] = Serdes.fromFn( //serializer
(request:PredictRequest) => request.toByteArray, //deserializer
(requestBytes:Array[Byte]) =>
Option(PredictRequest.parseFrom(requestBytes)))
The requirement for ML prediction in real time becomes more and more popular, and often it imposes quite a few challenges on data streaming pipelines. The common and most solid approaches are usually to use either Spark or Flink, mostly because they have support for ML and for some Python use cases. One of the disadvantages of these approaches, however, is that they usually require to maintain a dedicated compute cluster and that will sometimes be too costly or an overkill.
In this post I tried to sketch a different approach, based on Kafka Streams, which does not required an additional compute cluster other than your application server and the streaming platform that you are already using. As an example for a production grade ML model I used XGBoost classifier and showed how a model trained in a Python environment can be easily wrapped in a Scala object and used for inference on streaming data. When Kafka is used as a streaming platform, then using a KS application would almost always be competitive in terms of required development, maintenance, and performance efforts.
Hope this will be helpful!
Boost the performance of your Python-trained ML models by serving them over your Kafka streaming platform in a Scala application
Suppose you have a robust streaming platform based on Kafka, which cleans and enriches your customers’ event data before writing it to some warehouse. One day, during a casual planning meeting, your product manager raises the requirement to use a machine learning model (developed by the data science team) over incoming data and generate an alert for messages marked by the model. “No problem”, you reply. “We can select any data set we want from the data warehouse, and then run whatever model we want”. “Not exactly”, the PM replies. “We want this to run as real-time as possible. We want the results of the ML model to be available for consumption in a Kafka topic in less than a minute after we receive the event”.
This is a common requirement, and it will only get more popular. The requirement for real time ML inference on streaming data becomes important for many customers that have to make time-sensitive decisions on the result of the model.
It seems that big data engineering and data science play nicely together and should have some straightforward solution, but often that is not the case, and using ML for near real time inference over heavy workloads of data involves quite a few challenges. Among these challenges, for example, is the difference between Python, which is the dominant language of ML, and the JVM environment (Java/Scala) which is the dominant environment for big data engineering and data streaming. Another challenge relates to the data platform we are using for our workloads. If you are already working with Spark then you have the Spark ML lib at your service, but sometimes it will not be good enough, and sometimes (as in our case) Spark is not part of our stack or infra.
Its true that the ecosystem is aware of these challenges and is slowly addressing them with new features, though our specific and common scenario currently leaves you with a few common options. One, for example, is to add Spark to your stack and write a pySpark job that will add the ML inference stage to your pipeline. This is will offer better support for Python for your data science team but it also means that your data processing flow might take longer and that you also need to add and maintain a Spark cluster to your stack. Another option would be to use some third-party model serving platform that will expose an inference service endpoint based on your model. This might help you retain your performance but might also require the cost of additional infra while being an overkill for the some tasks.
In this post, I want to show another approach to this task using Kafka Streams. The advantage of using Kafka Streams for this task is that unlike Flink or Spark, it does not require a dedicated compute cluster. Rather, it can run on any application server or container environment you are already using, and if you are already using Kafka for stream processing, then it can be embedded in your flow quite seamlessly.
While both Spark and Flink have their machine learning libraries and tutorials, using Kafka Streams for this task seems like a less common use case , and my goal is to show how easy it is to implement. Specifically, I show how we can use an XGBoost model — a production grade machine learning model, trained in a Python environment, for real time inference over a stream of events on a Kafka topic.
This is intended to be a very hands-on post. In Section 2, we train an XGBoost classifier on a fraud detection dateset. We do so in a Jupyter notebook in a Python environment. Section 3 is an example for how the model’s binary can be imported and wrapped in a Scala class, and Section 4 shows how this can be embedded in a Kafka Stream application and generate real time prediction on streaming data. At the end of the post you can find a link to a repo with the full code described here.
( Note that in many cases I use Scala in a very non-idiomatic way. I do so for the sake of clarity as idiomatic Scala can sometimes be confusing. )
For this example, we start by training a simple classification model based on the Kaggle credit fraud data set.¹ You can find the full model training code here. The important bit (below) is that after we (or our data scientists) are satisfied with the results of our model, we simply save it in its simple binary form. This binary is all we need to load the model in our Kafka Streams app.
In this section we start implementing our Kafka Streams application by first wrapping our machine learning model in a Scala object (a singleton), which we will use to run inference on incoming records. This object will implement a predict() method that our stream processing application will use over each of the streaming events. The method will receive a record ID and an array of fields or features and will return a tuple that consists of the record id and the score the model gave it.
XGBoost model loading and prediction in Scala is pretty straightforward (though it should be noted that support in more recent Scala versions might be limited). After initial imports, we start by loading the *trained* model to a Booster variable.
Implementing the predict() method is also fairly simple. Each of our events contains an array of 10 features or fields that we will need to provide as input to our model.
The object type that XGboost uses to wrap the input vector for prediction is a DMatrix, which can be constructed in a number of ways. I will use the dense matrix format, which is based on providing a flat array of floats that represents the model features or fields; the length of each vector (nCols); and the numbers of vectors in the data set (nRows). For example, if our model is used to run inference on a vector with 10 features or fields, and we want to predict one vector at a time, then our DMatrix will be instantiated with an array of floats with length = 10, nCols = 10, and nRows = 1 (because there is only one vector in the set).
That will do the work for our Classifier object that wraps a trained XGboost ML model. There will be one Classifier object with a predict() method that will be called for each record.
Before we get into the code and details of our streaming application and show how we can use our Classifier on streaming data, its important to highlight the advantage and motivation of using Kafka Streams in such a system.
With Spark, just for example, distribution of compute is done by a cluster manager, that receives instructions from a driver application and distributes compute tasks to executors nodes in a dedicated cluster. Each Spark executor is responsible to process a set of partitions of the data. The power of Kafka Streams (KS) is that although it similarly achieves scale with parallelism — i.e., by running multiple replicas of the stream processing app, it does not depend on a dedicated cluster for that, but only on Kafka. In other words, the lifecycle of the compute nodes can be managed by any container orchestration system (such as K8S) or any other application server while leaving the coordination and management to Kafka (and the KS library). This may seem like a minor advantage, but this is exactly Spark’s greatest pain.
Indeed, unlike Spark, KS is a library that can be imported into any JVM-based application and, most importantly, run on any application infrastructure. A KS application typically reads streaming messages from a Kafka topic, performs its transformations, and writes the results to an output topic. State and stateful transformations, such as aggregations or windowed computations, are persisted and managed by Kafka, and scale is achieved by simply running more instances of your application (limited by the number of partitions the topic has and the consumer policy).
The basis of a KS app is a Topology, which defines the stream processing logic of the application or how input data is transformed into output data. In our case, the topology will run as follows
The topology here is fairly simple. It starts by reading streaming records from the input topic on Kafka, then it uses a map operation to run the model’s predict method on each record, and finally it splits the stream, and sends record ids that recived a high score from the model to a “suspicious events” output topic and the rest to another. Lets see how this looks in code.
Our starting point is the builder.stream method which starts reading messages from inputTopic topic on Kafka. I will shortly explain it more, but note that we are serializing each kafka record key as String and its payload as an object of type PredictRequest. PredictRequest is a Scala case class that corresponds to the protobuf schema below. This ensures that integration with message producers is straight forward but also makes is easier to generate the de/serialization methods that we are required to provide when dealing with custom objects.
message PredictRequest{
string recordID = 1;
repeated float featuresVector = 4;
}
Next, we use map() to call our classifier’s predict() method on the array that each message carries. Recall that this method returns a tuple of recordID and score, which is streamed back from the map operation. Finally, we use the split() method to create 2 branches of the stream — one for results higher than 0.5 and one for the others. We then send each branch of the stream to their own designated topic. Any consumer subsribed to the output topic will now recieve an alert for a suspicious record id (hopefully) near real time
One last comment on serialization:
Using custom classes or objects in a KS app written in Scala, either for the key or the value of the Kafka record, requires you to make available an implicit Serde[T] for the type (which includes its serializer and deserializer). Since I used a proto object as the message payload, much of the heavy lifting was done by scalapbc which “compiles” a proto schema to a Scala class that already contains the important methods to de/serialize the class. Making this implicit val available to the stream method (either in scope or by import ) enable this.
implicit val RequestSerde: Serde[PredictRequest] = Serdes.fromFn( //serializer
(request:PredictRequest) => request.toByteArray, //deserializer
(requestBytes:Array[Byte]) =>
Option(PredictRequest.parseFrom(requestBytes)))
The requirement for ML prediction in real time becomes more and more popular, and often it imposes quite a few challenges on data streaming pipelines. The common and most solid approaches are usually to use either Spark or Flink, mostly because they have support for ML and for some Python use cases. One of the disadvantages of these approaches, however, is that they usually require to maintain a dedicated compute cluster and that will sometimes be too costly or an overkill.
In this post I tried to sketch a different approach, based on Kafka Streams, which does not required an additional compute cluster other than your application server and the streaming platform that you are already using. As an example for a production grade ML model I used XGBoost classifier and showed how a model trained in a Python environment can be easily wrapped in a Scala object and used for inference on streaming data. When Kafka is used as a streaming platform, then using a KS application would almost always be competitive in terms of required development, maintenance, and performance efforts.
Hope this will be helpful!
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.