
Navigating Data in Datathons: Insights and Guidelines at Neural Information Processing Systems…
Navigating Data in Datathons: Insights and Guidelines [NeurIPS’23]
How to data in datathons
What is a datathon?
Datathons or data hackathons, loosely defined as data or data science-centric hackathons, have become increasingly popular in recent years, providing a platform for participants and organisations to collaborate, innovate, and learn in the area of data science over a short timeframe.
These events challenge participants to tackle data-related problems within a constrained timeframe, necessitating an understanding of data science and an acute awareness of the data being used.
What is the problem?
Datathons, high-energy events where data science and machine learning practicioners come together to solve pressing problems, are as much about innovation as they are about the effective handling of data.
Despite the significant and potential benefits of datathons, organizations often struggle to work with data effectively due to a lack of clear guidelines and best practices for potential issues that might arise.
What is the goal of this blog?
This blog post, written out of a Neural Information Processing Systems Conference 2023 paper on “How to Data in Datathons,” dives into critical aspects of preparing and selecting data for datathons, addressing:
— What does it mean for data to be appropriate for a datathon?
— How much data is enough data?
— How can we identify, categorise, and use sensitive data?
— Is the data analysis ready?
— Is the data reliable?
This framework is drawn from The Alan Turing Institute's experiences and insights from organizing 80+ datathon challenges with 60+ partnership organizations since 2016!!
It aims to offer a set of guidelines and recommendations to prepare different data types for datathons drawn from extensive experience in datathon organisation. If interested, consider participating in one of the Data Study Group events as a participant or as a challenge owner; more info [here]
Assessing Data in Datathons

When it comes to datathons, not just any data will do. The data needs to be ‘appropriate,’ ‘sufficient,’ and sensitive to privacy concerns. Organizers and participants often grapple with questions like: What makes data suitable for a datathon? How much data is considered enough? How do we handle sensitive data? Each dimension is crucial for ensuring the data used in datathons is suitable, ethical, and conducive to achieving the event’s objectives. Let’s dive into these aspects one by one.
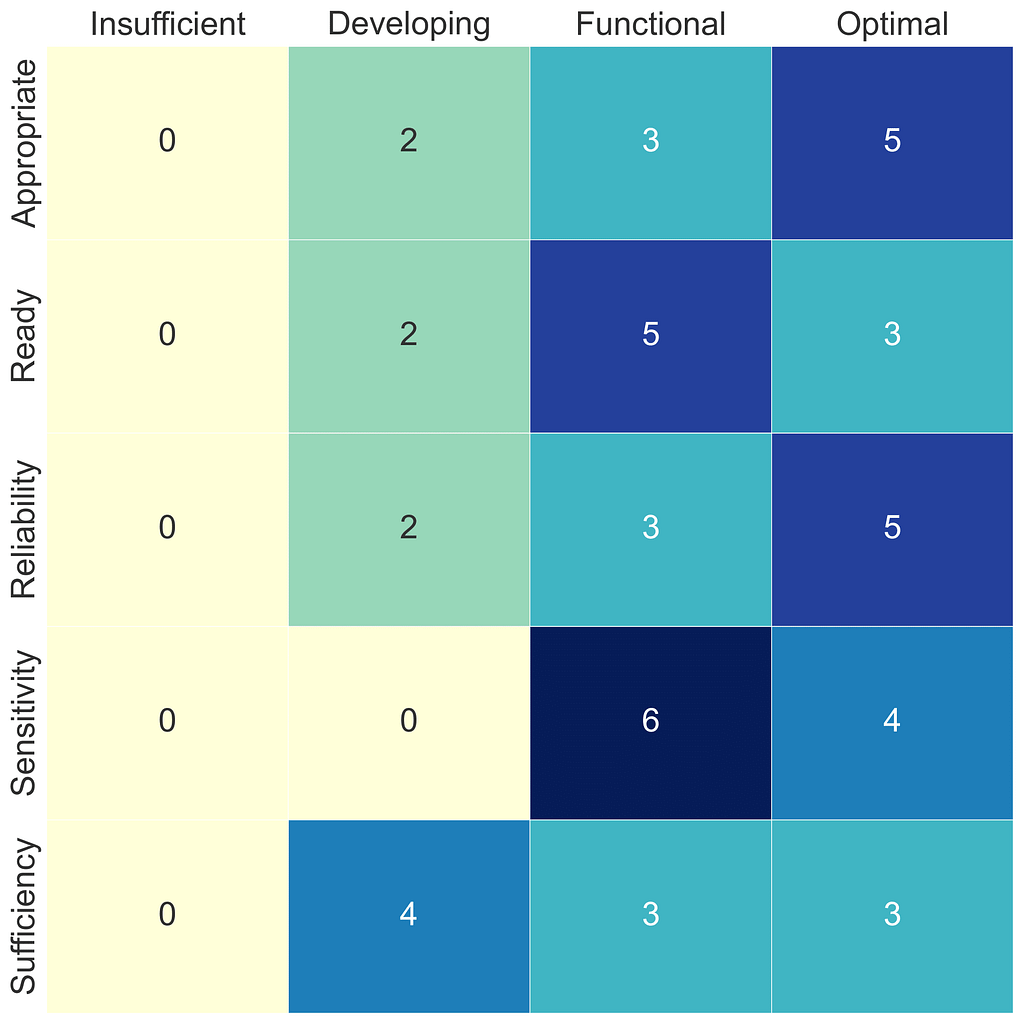
1. Data Appropriateness
The appropriateness of data concerns its relevance and utility in addressing the datathon’s specific challenge questions. This dimension evaluates whether the data provided aligns with the objectives of the datathon, ensuring that participants have the right kind of data to work with.
- Insufficient: The data has no apparent connection to the datathon’s goals, making it impossible for participants to use it effectively. For instance, providing weather data for a challenge focused on financial forecasting is entirely off-mark.
- Developing: While the data is somewhat related to the challenge, it lacks critical elements or target variables necessary for a comprehensive analysis or solution development.
- Functional: The data is relevant and can be directly applied to the challenge. However, there are opportunities for enhancing its value through the inclusion of additional variables or more detailed metadata that could provide deeper insights.
- Optimal: The provided data perfectly matches the challenge requirements, including a rich set of features, relevant target variables, and comprehensive metadata. This level represents an ideal scenario where participants have access to all necessary information for analysis and solution development.
2. Data Readiness
Readiness assesses the condition of the data regarding its preparation for immediate analysis. It involves factors such as data cleanliness, completeness, structure, and accessibility, which significantly impact the efficiency of the datathon.
- Insufficient: Data is either not collected or so poorly organized that significant effort is required to make it usable. This scenario poses a severe limitation on what can be achieved during the datathon timeframe.
- Developing: Data has been collected, but it may be incomplete, inconsistently formatted, or lacking in documentation, necessitating preliminary work before meaningful analysis can begin.
- Functional: While the data requires some cleaning or preprocessing, it is largely in a state that allows for analysis. Minor efforts may be needed to consolidate data sources or format data correctly.
- Optimal: Data is in an analysis-ready state, being well-documented, clean, and structured. Participants can focus on applying data science techniques rather than on data preparation tasks.
3. Data Reliability
Reliability pertains to the accuracy and bias in the data. It questions the extent to which data can be considered a truthful representation of the phenomena or population it is supposed to depict.
- Insufficient: The data is heavily biased or contains significant errors that could lead to misleading conclusions. Such data might misrepresent certain groups or phenomena, skewing analysis results.
- Developing: The reliability of the data is uncertain due to unknown sources of bias or potential errors in data collection and recording. This status calls for caution in interpretation and may limit the confidence in the outcomes.
- Functional: Known biases or issues exist but can be addressed through careful analysis or acknowledged as limitations of the study. This level of reliability requires transparency about the data’s limitations.
- Optimal: The data is considered highly reliable, with no known significant biases or errors. It accurately represents the target phenomena, allowing for confident and robust analysis.
4. Data Sensitivity
Sensitivity deals with the data’s privacy, confidentiality, and ethical considerations. It evaluates the level of risk associated with using and sharing the data, particularly concerning personal or proprietary information.
- Insufficient (Tier 4): Data is highly sensitive, posing significant legal, ethical, or personal risks. Such data is typically not suitable for datathons due to the high potential for misuse or harm.
- Developing (Tier 3): While not as critically sensitive, the data still requires stringent measures to protect privacy and confidentiality, possibly limiting its usability in a freely collaborative environment like a datathon.
- Functional (Tier 2): Data sensitivity is managed through de-identification or other safeguards, but attention to data protection remains important. Participants must be mindful of privacy considerations during their analysis.
- Optimal (Tier 0/1): The data presents minimal sensitivity risks, allowing for more straightforward sharing and analysis. This level is ideal for fostering open collaboration without compromising privacy or ethical standards.
5. Sufficiency
Sufficiency evaluates whether the amount and type of data provided are adequate to address the challenge questions effectively. It considers the volume, variety, and granularity of the data in relation to the datathon’s goals.
- Insufficient: The data volume or diversity is too limited to allow for meaningful analysis or to draw reliable conclusions. Such insufficiency can severely hamper the success of the datathon.
- Developing: Although some data is available, its quantity or quality may not be sufficient to explore the challenge questions fully or to build robust models. Participants may find it challenging to achieve significant insights.
- Functional: The data provided is adequate to engage with the challenge questions meaningfully. While not exhaustive, it enables participants to derive useful insights and propose viable solutions.
- Optimal: The data is abundant and varied, exceeding the basic requirements for the datathon. This level provides a rich playground for participants to explore innovative solutions and conduct thorough analyses.
Insights and Reccomendations
Data Study Groups (DSGs) are an award-winning collaborative datathon event organised by The Alan Turing Institute, the UK’s national institute for data science and artificial intelligence. ADSGs consist on a datathons that is worked collaboratively by a single team (rather than multiple teams competing with each other). The aim of DSGs is to provide opportunities for organisations and participants from academia and industry to work together to solve real-world challenges using data science and ML methodologies. The DSGs are managed and prepared by a specialised internal team of event organisers and interdisciplinary academic support staff. More info [here]
A successful datathon is the result of preparation, flexibility, and the collective effort of organizers, challenge owners, and participants. We outline the following reccomendations.
Before the Event: Collaborate and Align
The groundwork for a successful datathon is laid well before the event. Early engagement with challenge owners (business partners) is crucial. Their domain expertise and understanding of the data can significantly shape the event’s direction and outcomes. Their understanding of the problem and domain expertise can greatly improve the data, and early collaboration helps align the objectives and expectations on both sides, increasing the likelihood of a fruitful event.
As the datathon approaches, it is beneficial to do sanity checks on data readiness and consider changing the challenge questions based on input from an experience investigator that is able to align the industry requirements and the research requirements taking into consideration the perspective of participants.
During the Datathon: Adapt and Engage
The live event is where planning meets reality. PIs play a crucial role in guiding participants through data challenges and ensuring the objectives are met. Additionally, participant feedback is a goldmine. Their fresh eyes on the data can uncover new insights or identify areas for improvement, making the datathon a dynamic environment where adjustments are not just possible but encouraged.
Interested in real use cases? In the proceedings paper, we mapped 10 use cases to our framework.
- Cefas: Centre for Environment, Fisheries and Aquaculture Science
- The University of Sheffield Advanced Manufacturing Research Centre: Multi-sensor-based Intelligent Machining Process Monitoring
- CityMaaS: Making Travel for People in Cities Accessible through Prediction and Personalisation
- WWF: Smart Monitoring for Conservation Areas
- British Antarctic Survey: Seals from Space
- DWP: Department for Work and Pension
- Dementia Research Institute and DEMON Network: Predicting Functional Relationship between DNA Sequence and the Epigenetic State
- Automating Perfusion Assessment of Sublingual Microcirculation in Critical Illness
- Entale: Recommendation Systems for Podcast Discovery
- Odin Vision: Exploring AI-Supported Decision-Making for Early-Stage Diagnosis of Colorectal Cancer
The full reports, along with the outcome of other Data Study Groups, can be found at [Reports Section]
Conclusion
In this paper, we have analysed data in the context of datathons along five key dimensions: appropriateness, readiness, reliability, sensitivity and sufficiency, drawn from organizing 80+ datathons since 2016. By doing so, we hope to improve the handling of data for organisations prior to datathon events.
Our proposed qualitative analysis provides a degree of data status across several perspectives; these degrees can be adapted or extended, similar to the Technology Readiness Levels provided by NASA, which have been extended through time and further work.
Bibtex Citation:
@inproceedings{
mougan2023how,
title={How to Data in Datathons},
author={Carlos Mougan and Richard Plant and Clare Teng and Marya Bazzi and Alvaro Cabrejas-Egea and Ryan Sze-Yin Chan and David Salvador Jasin and martin stoffel and Kirstie Jane Whitaker and JULES MANSER},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2023},
url={https://openreview.net/forum?id=bjvRVA2ihO}
}
Mougan, C., Plant, R., Teng, C., Bazzi, M., Cabrejas-Egea, A., Chan, R. S.-Y., Jasin, D. S., Stoffel, M., Whitaker, K. J., & Manser, J. (2023). How to data in datathons. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
Navigating Data in Datathons: Insights and Guidelines at Neural Information Processing Systems… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Navigating Data in Datathons: Insights and Guidelines [NeurIPS’23]
How to data in datathons
What is a datathon?
Datathons or data hackathons, loosely defined as data or data science-centric hackathons, have become increasingly popular in recent years, providing a platform for participants and organisations to collaborate, innovate, and learn in the area of data science over a short timeframe.
These events challenge participants to tackle data-related problems within a constrained timeframe, necessitating an understanding of data science and an acute awareness of the data being used.
What is the problem?
Datathons, high-energy events where data science and machine learning practicioners come together to solve pressing problems, are as much about innovation as they are about the effective handling of data.
Despite the significant and potential benefits of datathons, organizations often struggle to work with data effectively due to a lack of clear guidelines and best practices for potential issues that might arise.
What is the goal of this blog?
This blog post, written out of a Neural Information Processing Systems Conference 2023 paper on “How to Data in Datathons,” dives into critical aspects of preparing and selecting data for datathons, addressing:
— What does it mean for data to be appropriate for a datathon?
— How much data is enough data?
— How can we identify, categorise, and use sensitive data?
— Is the data analysis ready?
— Is the data reliable?
This framework is drawn from The Alan Turing Institute's experiences and insights from organizing 80+ datathon challenges with 60+ partnership organizations since 2016!!
It aims to offer a set of guidelines and recommendations to prepare different data types for datathons drawn from extensive experience in datathon organisation. If interested, consider participating in one of the Data Study Group events as a participant or as a challenge owner; more info [here]

Assessing Data in Datathons
When it comes to datathons, not just any data will do. The data needs to be ‘appropriate,’ ‘sufficient,’ and sensitive to privacy concerns. Organizers and participants often grapple with questions like: What makes data suitable for a datathon? How much data is considered enough? How do we handle sensitive data? Each dimension is crucial for ensuring the data used in datathons is suitable, ethical, and conducive to achieving the event’s objectives. Let’s dive into these aspects one by one.
1. Data Appropriateness
The appropriateness of data concerns its relevance and utility in addressing the datathon’s specific challenge questions. This dimension evaluates whether the data provided aligns with the objectives of the datathon, ensuring that participants have the right kind of data to work with.
- Insufficient: The data has no apparent connection to the datathon’s goals, making it impossible for participants to use it effectively. For instance, providing weather data for a challenge focused on financial forecasting is entirely off-mark.
- Developing: While the data is somewhat related to the challenge, it lacks critical elements or target variables necessary for a comprehensive analysis or solution development.
- Functional: The data is relevant and can be directly applied to the challenge. However, there are opportunities for enhancing its value through the inclusion of additional variables or more detailed metadata that could provide deeper insights.
- Optimal: The provided data perfectly matches the challenge requirements, including a rich set of features, relevant target variables, and comprehensive metadata. This level represents an ideal scenario where participants have access to all necessary information for analysis and solution development.
2. Data Readiness
Readiness assesses the condition of the data regarding its preparation for immediate analysis. It involves factors such as data cleanliness, completeness, structure, and accessibility, which significantly impact the efficiency of the datathon.
- Insufficient: Data is either not collected or so poorly organized that significant effort is required to make it usable. This scenario poses a severe limitation on what can be achieved during the datathon timeframe.
- Developing: Data has been collected, but it may be incomplete, inconsistently formatted, or lacking in documentation, necessitating preliminary work before meaningful analysis can begin.
- Functional: While the data requires some cleaning or preprocessing, it is largely in a state that allows for analysis. Minor efforts may be needed to consolidate data sources or format data correctly.
- Optimal: Data is in an analysis-ready state, being well-documented, clean, and structured. Participants can focus on applying data science techniques rather than on data preparation tasks.
3. Data Reliability
Reliability pertains to the accuracy and bias in the data. It questions the extent to which data can be considered a truthful representation of the phenomena or population it is supposed to depict.
- Insufficient: The data is heavily biased or contains significant errors that could lead to misleading conclusions. Such data might misrepresent certain groups or phenomena, skewing analysis results.
- Developing: The reliability of the data is uncertain due to unknown sources of bias or potential errors in data collection and recording. This status calls for caution in interpretation and may limit the confidence in the outcomes.
- Functional: Known biases or issues exist but can be addressed through careful analysis or acknowledged as limitations of the study. This level of reliability requires transparency about the data’s limitations.
- Optimal: The data is considered highly reliable, with no known significant biases or errors. It accurately represents the target phenomena, allowing for confident and robust analysis.
4. Data Sensitivity
Sensitivity deals with the data’s privacy, confidentiality, and ethical considerations. It evaluates the level of risk associated with using and sharing the data, particularly concerning personal or proprietary information.
- Insufficient (Tier 4): Data is highly sensitive, posing significant legal, ethical, or personal risks. Such data is typically not suitable for datathons due to the high potential for misuse or harm.
- Developing (Tier 3): While not as critically sensitive, the data still requires stringent measures to protect privacy and confidentiality, possibly limiting its usability in a freely collaborative environment like a datathon.
- Functional (Tier 2): Data sensitivity is managed through de-identification or other safeguards, but attention to data protection remains important. Participants must be mindful of privacy considerations during their analysis.
- Optimal (Tier 0/1): The data presents minimal sensitivity risks, allowing for more straightforward sharing and analysis. This level is ideal for fostering open collaboration without compromising privacy or ethical standards.
5. Sufficiency
Sufficiency evaluates whether the amount and type of data provided are adequate to address the challenge questions effectively. It considers the volume, variety, and granularity of the data in relation to the datathon’s goals.
- Insufficient: The data volume or diversity is too limited to allow for meaningful analysis or to draw reliable conclusions. Such insufficiency can severely hamper the success of the datathon.
- Developing: Although some data is available, its quantity or quality may not be sufficient to explore the challenge questions fully or to build robust models. Participants may find it challenging to achieve significant insights.
- Functional: The data provided is adequate to engage with the challenge questions meaningfully. While not exhaustive, it enables participants to derive useful insights and propose viable solutions.
- Optimal: The data is abundant and varied, exceeding the basic requirements for the datathon. This level provides a rich playground for participants to explore innovative solutions and conduct thorough analyses.
Insights and Reccomendations
Data Study Groups (DSGs) are an award-winning collaborative datathon event organised by The Alan Turing Institute, the UK’s national institute for data science and artificial intelligence. ADSGs consist on a datathons that is worked collaboratively by a single team (rather than multiple teams competing with each other). The aim of DSGs is to provide opportunities for organisations and participants from academia and industry to work together to solve real-world challenges using data science and ML methodologies. The DSGs are managed and prepared by a specialised internal team of event organisers and interdisciplinary academic support staff. More info [here]
A successful datathon is the result of preparation, flexibility, and the collective effort of organizers, challenge owners, and participants. We outline the following reccomendations.
Before the Event: Collaborate and Align
The groundwork for a successful datathon is laid well before the event. Early engagement with challenge owners (business partners) is crucial. Their domain expertise and understanding of the data can significantly shape the event’s direction and outcomes. Their understanding of the problem and domain expertise can greatly improve the data, and early collaboration helps align the objectives and expectations on both sides, increasing the likelihood of a fruitful event.
As the datathon approaches, it is beneficial to do sanity checks on data readiness and consider changing the challenge questions based on input from an experience investigator that is able to align the industry requirements and the research requirements taking into consideration the perspective of participants.
During the Datathon: Adapt and Engage
The live event is where planning meets reality. PIs play a crucial role in guiding participants through data challenges and ensuring the objectives are met. Additionally, participant feedback is a goldmine. Their fresh eyes on the data can uncover new insights or identify areas for improvement, making the datathon a dynamic environment where adjustments are not just possible but encouraged.
Interested in real use cases? In the proceedings paper, we mapped 10 use cases to our framework.
- Cefas: Centre for Environment, Fisheries and Aquaculture Science
- The University of Sheffield Advanced Manufacturing Research Centre: Multi-sensor-based Intelligent Machining Process Monitoring
- CityMaaS: Making Travel for People in Cities Accessible through Prediction and Personalisation
- WWF: Smart Monitoring for Conservation Areas
- British Antarctic Survey: Seals from Space
- DWP: Department for Work and Pension
- Dementia Research Institute and DEMON Network: Predicting Functional Relationship between DNA Sequence and the Epigenetic State
- Automating Perfusion Assessment of Sublingual Microcirculation in Critical Illness
- Entale: Recommendation Systems for Podcast Discovery
- Odin Vision: Exploring AI-Supported Decision-Making for Early-Stage Diagnosis of Colorectal Cancer
The full reports, along with the outcome of other Data Study Groups, can be found at [Reports Section]
Conclusion
In this paper, we have analysed data in the context of datathons along five key dimensions: appropriateness, readiness, reliability, sensitivity and sufficiency, drawn from organizing 80+ datathons since 2016. By doing so, we hope to improve the handling of data for organisations prior to datathon events.
Our proposed qualitative analysis provides a degree of data status across several perspectives; these degrees can be adapted or extended, similar to the Technology Readiness Levels provided by NASA, which have been extended through time and further work.
Bibtex Citation:
@inproceedings{
mougan2023how,
title={How to Data in Datathons},
author={Carlos Mougan and Richard Plant and Clare Teng and Marya Bazzi and Alvaro Cabrejas-Egea and Ryan Sze-Yin Chan and David Salvador Jasin and martin stoffel and Kirstie Jane Whitaker and JULES MANSER},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2023},
url={https://openreview.net/forum?id=bjvRVA2ihO}
}
Mougan, C., Plant, R., Teng, C., Bazzi, M., Cabrejas-Egea, A., Chan, R. S.-Y., Jasin, D. S., Stoffel, M., Whitaker, K. J., & Manser, J. (2023). How to data in datathons. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
Navigating Data in Datathons: Insights and Guidelines at Neural Information Processing Systems… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.