
Why You Might Need To Know Algorithms as a Mobile Developer: Emoji Example
There is an infinite discussion about the topic of knowing algorithms and data structures for a frontend (in my case, mobile) developer needed only to pass technical interviews in large tech companies, or if there is some benefit of using it in daily work. I think the truth is somewhere in between, as always. Of course, you rarely find a case when you need to implement a min heap or use dynamic programming approaches while working on UI and business logic for a service with a REST API, but having a basic understanding of performance, time, and memory complexity can help make small, simple optimizations in the app that can pay off a lot in the long run.
I want to give an example of such a small optimization and decision-making process that can help us decide whether the extra effort is worth it or not.
Example
I’m working on a simple iOS application for my kids that should help them learn foreign languages. One of the basic functionalities is vocabulary where you can add a word you want to learn. I wanted to add some images for each word to visually represent it. However, in 2024, the best way may be to use an API of any image generation model, but it’s too much for the simple app I’m trying to make, so I decided to go with emojis. There are over 1,000 emojis available, and most simple words or phrases that kids can try to learn will have a visual representation there.
Here is a code example to obtain most of the emoji symbols and filter out only those that can be properly rendered.
var emojis: [Character: String] = [:]
let ranges = [
0x1F600...0x1F64F,
9100...9300,
0x2600...0x26FF,
0x2700...0x27BF,
0x1F300...0x1F5FF,
0x1F680...0x1F6FF,
0x1F900...0x1F9FF
]
for range in ranges {
for item in range {
guard
let scalar = UnicodeScalar(item),
scalar.properties.isEmojiPresentation
else {
continue
}
let value = Character(scalar)
emojis[value] = description(emoji: value)
}
}With each emoji character, we also store a description for it that we will use to find the right one for our word or phrase. Here are a few examples:
Now let’s consider how to find the right emoji for a given word or phrase in the most straightforward and simple way. Unfortunately, string comparing would not work here, as not all emojis contain a single word as a description, and the second is that users can use different versions of the word or even a phrase. Fortunately, Apple provides us with a built-in NaturalLanguage framework that can help us. We will utilize the sentence embedding functionality from it to measure the distance between the given word/phrase from the user and the emoji description we are storing.
Here is a function for it:
func calculateDistance(text: String, items: [Character]) -> (String?, Double?) {
guard let embedding = NLEmbedding.sentenceEmbedding(for: .english) else {
return (nil, nil)
}
var minDistance: Double = Double.greatestFiniteMagnitude
var emoji = ""
for key in items {
guard let value = emojis[key] else { continue }
let distance = embedding.distance(
between: text.lowercased(),
and: value.lowercased()
)
if distance < minDistance {
minDistance = distance
emoji = String(key)
}
}
return (emoji, minDistance)
}The algorithm is straightforward here: we run through all the emoji characters we have, taking a description and comparing it with the given text, saving the minimum distance found, and in the end, returning the emoji with the minimum distance to our text together with the distance itself for further filtering. This algorithm has a linear time complexity of O(n). Here are some examples of the results:
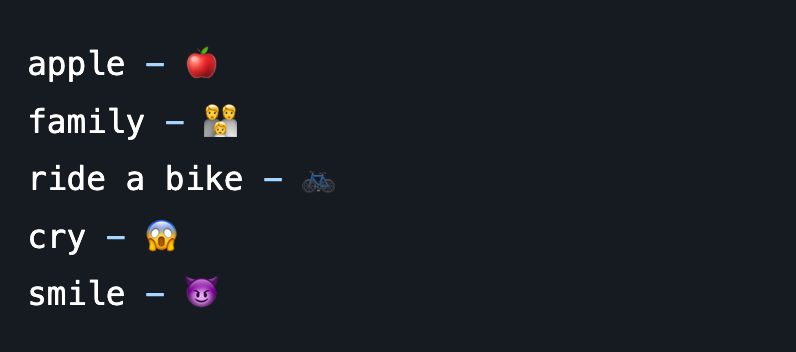
The last one is not what I would expect to get as a smiling face, but it is smiling, so it works. We can also use the returned distance to filter stuff out. The value of distance is in the range between 0 and 2 (by default). By running some experiments, I found that 0.85 is a great filter point for everything that does not represent the meaning of the phrase in the given emoji. Everything less than 0.85 looks good, and everything greater than that, I’m filtering out and returning an empty string to not confuse users.
We have a first version of our algorithm, and while it works, it’s quite slow. To find a match for any request, it needs to go through every emoji and execute distance measurements for each description individually. This process takes around 3.8 seconds for every request from the user.
Now we need to make an important decision: whether to invest time into optimization. To answer this question, let’s think about what exactly we want to improve by optimizing this extra effort. Even though 3.8 seconds for emoji generation may seem unacceptable, I would still use it as an example and challenge the purpose of optimizing this time. My use case is the following:
- The user opens the vocabulary and wants to add a new word or phrase.
- The user types this word.
- When typing is finished, I make a network call to a translation API that gives me a translation of the word.
- Ideally, I want this emoji to appear at the same time the typing is finished, but I can survive with a delay that will not exceed the time it takes for the translation API call and show it at the same time I’ve got the translation.
When I consider this behavior as a requirement, it’s clear that 3.8 seconds is too long for a network call. I would say if it takes 0.3-0.5 seconds, I probably wouldn’t optimize here because I wouldn’t want to sacrifice the user experience. Later, I might need to revisit this topic and improve it, but for now, delivering a working product is better than never delivering perfect code. In my case, I have to optimize, so let’s think about how to do it.
We’re already using a dictionary here, where emojis are keys and descriptions are values. We’ll add an additional dictionary with swapped keys and values. Additionally, I’ll split each description into separate words and use these words as keys. For the values, I’ll use a list of emojis that correspond to each word in the description. To make this more efficient, I’ll create an index for my emojis that can help me find the most relevant description for a given word in almost constant time. The main drawback of this approach is that it will only work with single words, not phrases. According to my target users, they will typically search for a single word. So, I’ll use this index for single-word searches and keep the old approach for rare phrases that won’t return an empty symbol in most cases by not finding an appropriate emoji explanation. Let’s take a look at a few examples from the Index dictionary:

And here’s a function for such index creation:
var searchIndex: [String: [Character]] = [:]
...
func prepareIndex() {
for item in emojis {
let words = item.value.components(separatedBy: " ")
for word in words {
var emojiItems: [Character] = []
let lowercasedWord = word.lowercased()
if let items = searchIndex[lowercasedWord] {
emojiItems = items
}
emojiItems.append(item.key)
searchIndex[lowercasedWord] = emojiItems
}
}
}Now, let’s add two more functions for single words and phrases.
func emoji(word: String) -> String {
guard let options = searchIndex[word.lowercased()] else {
return emoji(text: word)
}
let result = calculateDistance(text: word, items: options)
guard let value = result.0, let distance = result.1 else {
return emoji(text: word)
}
return distance < singleWordAllowedDistance ? value : ""
}
func emoji(text: String) -> String {
let result = calculateDistance(text: text, items: Array(emojis.keys))
guard let value = result.0, let distance = result.1 else {
return ""
}
return distance < allowedDistance ? value : ""
}allowedDistance and singleWordAllowedDistance are constants that help me to configure filtering.
As you can see, we use the same distance calculation as before, but instead of all emojis, we’re injecting a list of emojis that have the given word in their description. And for most cases, it will be just a few or even only one option. This makes the algorithm work in near constant time in most cases. Let’s test it and measure the time. This updated algorithm gives a result within 0.04 – 0.08 seconds, which is around 50 times faster than before. However, there’s a big issue: the words should be spelled exactly as they are presented in the description. We can fix this by using a Word Embedding with Neighbors function, which will give us a list of similar or close-in-meaning words to the given one. Here’s an updated func emoji(word: String) -> String function.
func emoji(word: String) -> String {
guard let wordEmbedding = NLEmbedding.wordEmbedding(for: .english) else {
return ""
}
let neighbors = wordEmbedding.neighbors(for: word, maximumCount: 2).map({ $0.0 })
let words = [word] + neighbors
for word in words {
guard let options = searchIndex[word.lowercased()] else {
continue
}
let result = calculateDistance(text: word, items: options)
guard let value = result.0, let distance = result.1 else {
return emoji(text: word)
}
return distance < singleWordAllowedDistance ? value : ""
}
return emoji(text: word)
}Now it works very quickly and in most cases.
Conclusion
Knowing basic algorithms and data structures expands your toolset and helps you find areas in code that can be optimized. Especially when working on a large project with many developers and numerous modules in the application, having optimizations here and there will help the app run faster over time.
There is an infinite discussion about the topic of knowing algorithms and data structures for a frontend (in my case, mobile) developer needed only to pass technical interviews in large tech companies, or if there is some benefit of using it in daily work. I think the truth is somewhere in between, as always. Of course, you rarely find a case when you need to implement a min heap or use dynamic programming approaches while working on UI and business logic for a service with a REST API, but having a basic understanding of performance, time, and memory complexity can help make small, simple optimizations in the app that can pay off a lot in the long run.
I want to give an example of such a small optimization and decision-making process that can help us decide whether the extra effort is worth it or not.
Example
I’m working on a simple iOS application for my kids that should help them learn foreign languages. One of the basic functionalities is vocabulary where you can add a word you want to learn. I wanted to add some images for each word to visually represent it. However, in 2024, the best way may be to use an API of any image generation model, but it’s too much for the simple app I’m trying to make, so I decided to go with emojis. There are over 1,000 emojis available, and most simple words or phrases that kids can try to learn will have a visual representation there.
Here is a code example to obtain most of the emoji symbols and filter out only those that can be properly rendered.
var emojis: [Character: String] = [:]
let ranges = [
0x1F600...0x1F64F,
9100...9300,
0x2600...0x26FF,
0x2700...0x27BF,
0x1F300...0x1F5FF,
0x1F680...0x1F6FF,
0x1F900...0x1F9FF
]
for range in ranges {
for item in range {
guard
let scalar = UnicodeScalar(item),
scalar.properties.isEmojiPresentation
else {
continue
}
let value = Character(scalar)
emojis[value] = description(emoji: value)
}
}With each emoji character, we also store a description for it that we will use to find the right one for our word or phrase. Here are a few examples:

Now let’s consider how to find the right emoji for a given word or phrase in the most straightforward and simple way. Unfortunately, string comparing would not work here, as not all emojis contain a single word as a description, and the second is that users can use different versions of the word or even a phrase. Fortunately, Apple provides us with a built-in NaturalLanguage framework that can help us. We will utilize the sentence embedding functionality from it to measure the distance between the given word/phrase from the user and the emoji description we are storing.
Here is a function for it:
func calculateDistance(text: String, items: [Character]) -> (String?, Double?) {
guard let embedding = NLEmbedding.sentenceEmbedding(for: .english) else {
return (nil, nil)
}
var minDistance: Double = Double.greatestFiniteMagnitude
var emoji = ""
for key in items {
guard let value = emojis[key] else { continue }
let distance = embedding.distance(
between: text.lowercased(),
and: value.lowercased()
)
if distance < minDistance {
minDistance = distance
emoji = String(key)
}
}
return (emoji, minDistance)
}The algorithm is straightforward here: we run through all the emoji characters we have, taking a description and comparing it with the given text, saving the minimum distance found, and in the end, returning the emoji with the minimum distance to our text together with the distance itself for further filtering. This algorithm has a linear time complexity of O(n). Here are some examples of the results:
The last one is not what I would expect to get as a smiling face, but it is smiling, so it works. We can also use the returned distance to filter stuff out. The value of distance is in the range between 0 and 2 (by default). By running some experiments, I found that 0.85 is a great filter point for everything that does not represent the meaning of the phrase in the given emoji. Everything less than 0.85 looks good, and everything greater than that, I’m filtering out and returning an empty string to not confuse users.
We have a first version of our algorithm, and while it works, it’s quite slow. To find a match for any request, it needs to go through every emoji and execute distance measurements for each description individually. This process takes around 3.8 seconds for every request from the user.
Now we need to make an important decision: whether to invest time into optimization. To answer this question, let’s think about what exactly we want to improve by optimizing this extra effort. Even though 3.8 seconds for emoji generation may seem unacceptable, I would still use it as an example and challenge the purpose of optimizing this time. My use case is the following:
- The user opens the vocabulary and wants to add a new word or phrase.
- The user types this word.
- When typing is finished, I make a network call to a translation API that gives me a translation of the word.
- Ideally, I want this emoji to appear at the same time the typing is finished, but I can survive with a delay that will not exceed the time it takes for the translation API call and show it at the same time I’ve got the translation.
When I consider this behavior as a requirement, it’s clear that 3.8 seconds is too long for a network call. I would say if it takes 0.3-0.5 seconds, I probably wouldn’t optimize here because I wouldn’t want to sacrifice the user experience. Later, I might need to revisit this topic and improve it, but for now, delivering a working product is better than never delivering perfect code. In my case, I have to optimize, so let’s think about how to do it.
We’re already using a dictionary here, where emojis are keys and descriptions are values. We’ll add an additional dictionary with swapped keys and values. Additionally, I’ll split each description into separate words and use these words as keys. For the values, I’ll use a list of emojis that correspond to each word in the description. To make this more efficient, I’ll create an index for my emojis that can help me find the most relevant description for a given word in almost constant time. The main drawback of this approach is that it will only work with single words, not phrases. According to my target users, they will typically search for a single word. So, I’ll use this index for single-word searches and keep the old approach for rare phrases that won’t return an empty symbol in most cases by not finding an appropriate emoji explanation. Let’s take a look at a few examples from the Index dictionary:
And here’s a function for such index creation:
var searchIndex: [String: [Character]] = [:]
...
func prepareIndex() {
for item in emojis {
let words = item.value.components(separatedBy: " ")
for word in words {
var emojiItems: [Character] = []
let lowercasedWord = word.lowercased()
if let items = searchIndex[lowercasedWord] {
emojiItems = items
}
emojiItems.append(item.key)
searchIndex[lowercasedWord] = emojiItems
}
}
}Now, let’s add two more functions for single words and phrases.
func emoji(word: String) -> String {
guard let options = searchIndex[word.lowercased()] else {
return emoji(text: word)
}
let result = calculateDistance(text: word, items: options)
guard let value = result.0, let distance = result.1 else {
return emoji(text: word)
}
return distance < singleWordAllowedDistance ? value : ""
}
func emoji(text: String) -> String {
let result = calculateDistance(text: text, items: Array(emojis.keys))
guard let value = result.0, let distance = result.1 else {
return ""
}
return distance < allowedDistance ? value : ""
}allowedDistance and singleWordAllowedDistance are constants that help me to configure filtering.
As you can see, we use the same distance calculation as before, but instead of all emojis, we’re injecting a list of emojis that have the given word in their description. And for most cases, it will be just a few or even only one option. This makes the algorithm work in near constant time in most cases. Let’s test it and measure the time. This updated algorithm gives a result within 0.04 – 0.08 seconds, which is around 50 times faster than before. However, there’s a big issue: the words should be spelled exactly as they are presented in the description. We can fix this by using a Word Embedding with Neighbors function, which will give us a list of similar or close-in-meaning words to the given one. Here’s an updated func emoji(word: String) -> String function.
func emoji(word: String) -> String {
guard let wordEmbedding = NLEmbedding.wordEmbedding(for: .english) else {
return ""
}
let neighbors = wordEmbedding.neighbors(for: word, maximumCount: 2).map({ $0.0 })
let words = [word] + neighbors
for word in words {
guard let options = searchIndex[word.lowercased()] else {
continue
}
let result = calculateDistance(text: word, items: options)
guard let value = result.0, let distance = result.1 else {
return emoji(text: word)
}
return distance < singleWordAllowedDistance ? value : ""
}
return emoji(text: word)
}Now it works very quickly and in most cases.
Conclusion
Knowing basic algorithms and data structures expands your toolset and helps you find areas in code that can be optimized. Especially when working on a large project with many developers and numerous modules in the application, having optimizations here and there will help the app run faster over time.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.